基础
-
Java简单类型
- byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。
- short:16位,最大数据存储量是65536,数据范围是-32768~32767之间。
- int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
- long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
- float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
- double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
- boolean:只有true和false两个取值。
- char:16位,存储Unicode码,用单引号赋值。
-
Java中的I/O流
-
BIO、NIO、AIO
- BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
- NIO (New I/O): NIO是一种同步非阻塞的I/O模型。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。
- AIO (Asynchronous I/O): AIO 也就是 NIO 2,是异步非阻塞的IO模型。
https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/BIO-NIO-AIO.md
同步与异步
同步: 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
异步: 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
阻塞和非阻塞
阻塞: 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
非阻塞: 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(同步阻塞)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
-
-
NIO
线程控制选择器,选择不同的通道来读取缓存区。
IO和NIO的区别
原有的 IO 是面向流的、阻塞的,NIO 则是面向块的、非阻塞的。
怎么理解IO是面向流的、阻塞的 java1.4以前的io模型,一连接对一个线程。
原始的IO是面向流的,不存在缓存的概念。Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区
Java IO的各种流是阻塞的,这意味着当一个线程调用read或 write方法时,该线程被阻塞,直到有一些数据被读取,或数据完全写入,该线程在此期间不能再干任何事情了。
怎么理解NIO是面向块的、非阻塞的
NIO是面向缓冲区的。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动,这就增加了处理过程中的灵活性。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
通俗理解:NIO是可以做到用一个线程来处理多个操作的。假设有10000个请求过来,根据实际情况,可以分配50或者100个线程来处理。不像之前的阻塞IO那样,非得分配10000个。
-
linux五种IO模型
Linux下主要有以下五种I/O模型:
- 阻塞I/O(blocking IO)
- 非阻塞I/O (nonblocking I/O)
- I/O 复用 (I/O multiplexing)
- 信号驱动I/O (signal driven I/O (SIGIO))
- 异步I/O (asynchronous I/O)
-
select、poll、eopll的区别
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
poll
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构。
epoll
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
-
Object类的方法
https://fangjian0423.github.io/2016/03/12/java-Object-method/
- getClass()
- hashCode()
- equals()
- clone()
- toString()
- notify(): 唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果所有的线程都在此对象上等待,那么只会选择一个线程。
- notifyAll(): 跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
- wait(long timeout) throws InterruptedException: wait方法会让当前线程等待直到另外一个线程调用对象的notify或notifyAll方法,或者超过参数设置的timeout超时时间。
- wait(long timeout, int nanos) throws InterruptedException: 跟wait(long timeout)方法类似,多了一个nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
- wait() throws InterruptedException: 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念。
- finalize()的作用是实例被垃圾回收器回收的时候触发的操作,就好比 “死前的最后一波挣扎”。
-
接口和抽象类的区别
- 方法在接口中不能有实现,而抽象类可以有非抽象方法。
- 接口中除了static、final变量,不能有其他变量。
- 一个类可以实现多个接口,但只能实现一个抽象类。接口可以通过extends关键字扩展多个接口。
- 接口方法默认是public,抽象方法可以有public、protected、default(不能使用private)。
- 抽象类是对类的抽象,接口是对行为的抽象。
-
面对对象语言的特点:封装、继承、多态(指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用))(引用变量指向哪个类的实例对象,引用对象发出的方法调用哪个类中的实现的方法,在程序运行期间才能确定)。
-
JVM、JDK、JRE
- Java虚拟机(JVM)实现平台无关性,是运行Java字节码(.class文件)的虚拟机。
- .java源代码(通过JDK中的javac编译).class字节码(通过JVM)机器码。
- JDK包括JRE、javac、jdb等,能够创建和编译程序;JRE是Java运行环境,用于运行已编译的Java程序,包括JVM等。
-
Java与C++的区别
- Java没有指针来直接访问内存,访问内存更安全。
- 有自动内存管理机制,不需要手动释放内存。
- Java的类是单继承的,接口可以多继承,C++支持多继承。
- Java字符串没有\0,因为Java里一切都是对象,可以确定长度。
-
Java的接口和C++的虚类的相同和不同处
- 由于Java不支持多继承,而有可能某个类或对象要使用分别在几个类或对象里面的方法或属性,现有的单继承机制就不能满足要求。
- 与继承相比,接口有更高的灵活性,因为接口中没有任何实现代码。当一个类实现了接口以后,该类要实现接口里面所有的方法和属性。
- C++虚类相当于java中的抽象类,一个子类只能继承一个抽象类(虚类),但能实现多个接口
- 一个抽象类可以有构造方法,接口没有构造方法
- 一个抽象类中的方法不一定是抽象方法,即其中的方法可以有实现(有方法体),接口中的方法都是抽象方法,不能有方法体,只有声明
- 一个抽象类可以是public、private、protected、default,接口只有public
- 一个抽象类中的方法可以是public、private、protected、default,接口中的方法只能是public和default
- 相同之处是:都不能实例化。
-
构造器(private方法)不能重写(override),但是可以重载(overload),一个类中可以有多个构造器。
-
重写(override)和重载(overload)的区别
-
方法的重写和重载都是实现多态的方式,区别在于前者实现的是运行的多态性,而后者实现的是编译时的多态性。
-
重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,不能比父类被重写方法声明更多的异常(里氏代换原则)
-
重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载。
-
重载是否区分返回值类型?重载不根据返回类型进行区分。
-
Overloaded的方法是否可以改变返回值的类型?
这个题目很模糊。如果几个Overloaded的方法的参数列表不一样,它们的返回者类型当然也可以不一样。但我估计你想问的问题是:如果两个方法的参数列表完全一样,是否可以让它们的返回值不同来实现重载Overload。这是不行的。
我们可以用反证法来说明这个问题,因为我们有时候调用一个方法时也可以不定义返回结果变量,即不要关心其返回结果,例如,我们调用map.remove(key)方法时,虽然remove方法有返回值,但是我们通常都不会定义接收返回结果的变量,这时候假设该类中有两个名称和参数列表完全相同的方法,仅仅是返回类型不同,java就无法确定编程者倒底是想调用哪个方法了,因为它无法通过返回结果类型来判断。
-
-
String、Stringbuffer、StringBuilder
- String类中使用final关键字修饰字符数组来保存字符串,对象不可变,线程安全。
- StringBuffer和StringBuilder构造方法调用父类AbstractStringBuffer实现,是可变的。
- StringBuffer对方法加了同步锁,是线程安全的;StringBuilder没有加同步锁,非线程安全。
- 底层实现上的话,StringBuffer其实就是比StringBuilder多了Synchronized修饰符。
-
装箱:基本类型用对应的引用类型包装起来。
拆箱:包装类型转换为基本数据类型。
-
静态方法内不能调用非静态成员,因为静态方法可以不通过对象进行调用。
-
不做事且没有参数的构造方法的作用:子类中没有用super()方法来调用父类特定的构造方法,会调用父类中没有参数的构造方法。
-
成员变量和局部变量的区别
- 成员变量属于类,局部变量是在方法中定义的变量或方法的参数;成员变量可以被public、private、static等修饰符修饰,局部变量不能被访问控制符及static所修饰;成员变量和局部变量都能被final修饰。
- 成员变量如果使用static修饰属于类,否则属于实例。对象存在堆中,局部变量存在栈中,静态变量存在方法区。
- 成员变量是对象的一部分,随着对象的创建而存在;局部变量随着方法的调用而自动消失。
- 成员变量如果没有赋初值会自动赋默认值,局部变量不会自动赋值。
-
构造方法
- 名字于类名相同。
- 没有返回值,不能用void声明构造函数。
- 生成类的对象时自动执行,无需调用。如果没有声明构造方法,会有默认的不带参数的构造函数。
- 作用时完成堆类对象的初始化工作。
-
静态方法和实例方法的区别
- 在外部调用静态方法:类名.方法名、对象名.方法名;实例方法:对象名.方法名。
- 静态方法在访问本类成员时,只允许访问静态成员(静态成员变量、静态方法),不允许访问实例成员变量和实例方法。
-
为什么Java中只有值传递
-
例1
1 2 3 4 5 6 7 8 9 10 11
public static void main(String[] args) { int[] arr = { 1, 2, 3, 4, 5 }; System.out.println(arr[0]); change(arr); System.out.println(arr[0]); } public static void change(int[] array) { // 将数组的第一个元素变为0 array[0] = 0; }
结果
1 2
1 0
解析:方法得到的是对象引用的拷贝,对象引用及对象引用的拷贝同时引用同一个对象。
-
例2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
public class Test { public static void main(String[] args) { // TODO Auto-generated method stub Student s1 = new Student("小张"); Student s2 = new Student("小李"); Test.swap(s1, s2); System.out.println("s1:" + s1.getName()); System.out.println("s2:" + s2.getName()); } public static void swap(Student x, Student y) { Student temp = x; x = y; y = temp; System.out.println("x:" + x.getName()); System.out.println("y:" + y.getName()); } }
结果
1 2 3 4
x:小李 y:小张 s1:小张 s2:小李
解析
交换之前:
交换之后:
方法并没有改变存储在变量s1和s2中的对象引用。
-
总结
Java中对对象采用的不是引用调用,对象引用是按值传递的,因此一个方法不能让对象参数引用一个新的对象。
-
-
Java中的异常处理
-
异常类层次结构
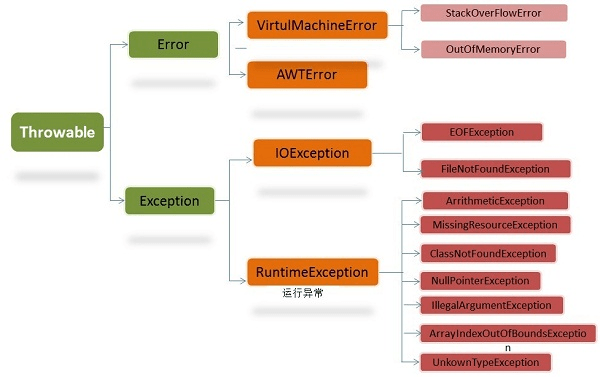
Throwable类分为两个子类:Exception(异常)和Error(错误)。
Error是程序无法处理的错误。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
Exception是程序本身可以处理的异常。Exception 类有一个重要的子类 RuntimeException。RuntimeException 异常由Java虚拟机抛出。NullPointerException(要访问的变量没有引用任何对象时,抛出该异常)、ArithmeticException(算术运算异常,一个整数除以0时,抛出该异常)和 ArrayIndexOutOfBoundsException (下标越界异常)。
-
异常处理总结
-
try 块: 用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
-
catch 块: 用于处理try捕获到的异常。
-
finally 块: 无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return 语句时,finally语句块将在方法返回之前被执行。
-
注意: 当try语句和finally语句中都有return语句时,在方法返回之前,finally语句的内容将被执行,并且finally语句的返回值将会覆盖原始的返回值。以下代码如果调用
f(2),返回值将是0,因为finally语句的返回值覆盖了try语句块的返回值。1 2 3 4 5 6 7 8 9
public static int f(int value) { try { return value * value; } finally { if (value == 2) { return 0; } } }
-
-
请说明JAVA语言如何进行异常处理,关键字:throws,throw,try,catch,finally分别代表什么意义?在try块中可以抛出异常吗?
-
throw:用来明确地抛出一个“异常”。
- throws:标明一个成员函数可能抛出的各种“异常”。
- 可以在try里手动抛出异常,不过比较少见;也可以在try里嵌套try。
-
-
-
受检异常和非受检异常
https://www.cnblogs.com/tjudzj/p/7053980.html
-
transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
-
获取用键盘输入的方法
-
通过 Scanner
1 2 3
Scanner input = new Scanner(System.in); String s = input.nextLine(); input.close();
-
通过 BufferedReader
1 2
BufferedReader input = new BufferedReader(new InputStreamReader(System.in)); String s = input.readLine();
-
-
static、final
- final关键字
- 对于一个final变量,如果是基本数据类型的变量,其数值在初始化后不能更改;如果是引用类型的变量,在对其初始化之后不能再让它指向另一个对象。
- 用final修饰一个类时,表示这个类不能被继承。final类的所有成员方法都会被隐式指定final方法。
- 使用final方法有两个原因。
- 把方法锁定,以防任何继承类修改它的含义。
- 效率。在早期的Java实现版本中,会将final方法转为内嵌调用。类中的所有private方法都隐式地指定为final。
- static关键字
- 修饰成员变量和成员方法: 被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。调用格式:
类名.静态变量名类名.静态方法名() - 静态代码块: 静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—>非静态代码块—>构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
- 静态内部类(static修饰类的话只能修饰内部类): 静态内部类与非静态内部类之间存在一个最大的区别: 非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着:1. 它的创建是不需要依赖外围类的创建。2. 它不能使用任何外围类的非static成员变量和方法。
- 静态导包(用来导入类中的静态资源,1.5之后的新特性): 格式为:
import static这两个关键字连用可以指定导入某个类中的指定静态资源,并且不需要使用类名调用类中静态成员,可以直接使用类中静态成员变量和成员方法。
- 修饰成员变量和成员方法: 被 static 修饰的成员属于类,不属于单个这个类的某个对象,被类中所有对象共享,可以并且建议通过类名调用。被static 声明的成员变量属于静态成员变量,静态变量 存放在 Java 内存区域的方法区。调用格式:
- final关键字
-
深拷贝、浅拷贝
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝。
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容。
-
Java和PHP/JavaScript、Python的区别
https://www.zhihu.com/question/20377398
https://www.zhihu.com/question/19913979
-
Java 属于强类型(所有程序都是well behaved),是静态类型语言(在编译时拒绝ill behaved)。
- PHP/JavaScript属于弱类型(不需要定义变量的类型),是动态类型语言(在运行时拒绝ill behaved)。
- PHP/JavaScript数组的功能强大,可以当作map和list来用。
- PHP主要用于服务器端,JavaScript主要用于网页端。
- Java和Python的区别是静态类型和动态类型,静态类型必须先声明再使用,动态则不需要声明。
- Python也是强类型。强弱类型不是指是否需要定义,而是是一旦类型决定了,是否能随便转换。
-
-
如何跳出多重循环
- loop and a half
- break
-
内部类可以引用他包含类的成员吗,如果可以,有没有什么限制吗?
-
一个内部类对象可以访问创建它的外部类对象的内容。内部类如果不是static的,那么它可以访问创建它的外部类对象的所有属性内部类;如果是satic的,即为nested class,那么它只可以访问创建它的外部类对象的所有static属性
-
完全可以。如果不是静态内部类,那没有什么限制! 如果你把静态嵌套类当作内部类的一种特例,那在这种情况下不可以访问外部类的普通成员变量,而只能访问外部类中的静态成员。
-
-
Static Nested Class 和 Inner Class的不同
Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化。而通常的内部类需要在外部类实例化后才能实例化。
-
final, finally, finalize的区别
- final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
- finally是异常处理语句结构的一部分,表示总是执行。
- finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
-
extends 和super 泛型限定符
-
在java泛型中,? 表示通配符,代表未知类型,< ? extends Object>表示上边界限定通配符,< ? super Object>表示下边界限定通配符。
-
通配符 与 T 的区别
- T:作用于模板上,用于将数据类型进行参数化,不能用于实例化对象。
- ?:在实例化对象的时候,不确定泛型参数的具体类型时,可以使用通配符进行对象定义。
- < T > 等同于 < T extends Object>
- < ? > 等同于 < ? extends Object>
-
例一:定义泛型类,将key,value的数据类型进行< K, V >参数化,而不可以使用通配符。
1 2 3 4 5 6 7 8 9
public class Container<K, V> { private K key; private V value; public Container(K k, V v) { key = k; value = v; } }
-
例二:实例化泛型对象,我们不能够确定eList存储的数据类型是Integer还是Long,因此我们使用List<? extends Number>定义变量的类型。
1 2 3
List<? extends Number> eList = null; eList = new ArrayList<Integer>(); eList = new ArrayList<Long>();
上界类型通配符(? extends)
1 2 3 4 5 6 7 8 9
List<? extends Number> eList = null; eList = new ArrayList<Integer>(); Number numObject = eList.get(0); //语句1,正确 //Type mismatch: cannot convert from capture#3-of ? extends Number to Integer Integer intObject = eList.get(0); //语句2,错误 //The method add(capture#3-of ? extends Number) in the type List<capture#3-of ? extends Number> is not applicable for the arguments (Integer) eList.add(new Integer(1)); //语句3,错误
-
-
泛型
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
-
Query接口的list方法和iterate方法有什么区别?
-
返回的类型不一样,list返回List,iterate返回iterator
-
查询策略不同。获取数据的方式不一样,list会直接查询数据库,iterate会先到数据库中把id取出来,然后真正要遍历某个对象的时候先到缓存中找,如果找不到,以id为条件再发一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1
-
iterate会查询2级缓存,list只会缓存,但不会使用缓存(除非结合查询缓存)。
-
list中返回的list中每个对象都是原本的对象,iterate中返回的对象中仅包含了主键值
-
-
汉字能用char类型来表示吗,一个汉字占多少字节?
char固定占用2个字节,用来储存Unicode字符。范围在065536。unicode编码字符集中包含了汉字,所以,char型变量中可以存储汉字。不过,如果某个特殊的汉字没有被包含在unicode编码字符集中,那么,这个char型变量中就不能存储这个特殊汉字。
https://www.cnblogs.com/kingcat/archive/2012/10/16/2726334.html
UTF-8 与UTF-16的区别
UTF-16比较好理解,就是任何字符对应的数字都用两个字节来保存.我们通常对Unicode的误解就是把Unicode与UTF-16等同了.但是很显然如果都是英文字母这做有点浪费.明明用一个字节能表示一个字符为啥整两个啊.
于是又有个UTF-8,这里的8非常容易误导人,8不是指一个字节,难道一个字节表示一个字符?实际上不是.当用UTF-8时表示一个字符是可变的,有可能是用一个字节表示一个字符,也可能是两个,三个.当然最多不能超过3个字节了.反正是根据字符对应的数字大小来确定.
-
一个方法被private和static修饰,能被override吗?为什么
不可以,
-
override:子类重写父类的方法(返回值,方法名,参数都相同)以实现多态。
-
private只能够被自身类访问,子类不能访问private修饰的成员,所有不能override一个private方法
-
static方法是与类绑定的与任何实例都无关,随着类的加载而加载, static是编译时静态绑定的,override是运行时动态绑定的。形式上static可以override,但是实际上并不能被override。
-
容器
-
List、Set、Map的区别
- List:有序的多个对象。
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向链表
- Set:不允许重复的集合。
- HashSet(无序,唯一): 基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
- Map:使用键值对存储。
- Set和Map容器都有基于哈希存储和排序树的两种实现版本,基于哈希存储的版本理论存取时间复杂度为O(1),而基于排序树版本的实现在插入或删除元素时会按照元素或元素的键(key)构成排序树从而达到排序和去重的效果。
- List:有序的多个对象。
-
Array和ArrayList的区别
- Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
- Array大小是固定的,ArrayList的大小是动态变化的。
- ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
-
ArrayList和LinkedList的区别
- 都不保证线程安全。
- 底层数据结构:ArrayList底层使用的Object数组,LinkedList底层使用的是双向链表结构。
- 时间复杂度:ArrayList插入删除元素的时间复杂度为O(n),取第 i 元素的时间复杂度为O(1);LinkedList插入和删除的时间复杂度为O(1),如果是要在指定位置i插入和删除元素的话,时间复杂度近似为O(n)因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:LinkedList不支持高效的随机元素访问,而 ArrayList 支持。
- 内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
-
ArrayList和Vector的区别
- Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
- Arraylist不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
-
Map的分类
- Map有4个实现类,HashMap、HashTable、LinkedHashMap、TreeMap。
- Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。 HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。
- Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
- LinkedHashMap 是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。
- TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
- 一般情况下,我们用的最多的是HashJDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点)Map,在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列.
-
HashMap源码学习
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // table未初始化或者长度为0,进行扩容 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中) if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 桶中已经存在元素 else { Node<K,V> e; K k; // 比较桶中第一个元素(数组中的结点)的hash值相等,key相等 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 将第一个元素赋值给e,用e来记录 e = p; // hash值不相等,即key不相等;为红黑树结点 else if (p instanceof TreeNode) // 放入树中 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 为链表结点 else { // 在链表最末插入结点 for (int binCount = 0; ; ++binCount) { // 到达链表的尾部 if ((e = p.next) == null) { // 在尾部插入新结点 p.next = newNode(hash, key, value, null); // 结点数量达到阈值,转化为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); // 跳出循环 break; } // 判断链表中结点的key值与插入的元素的key值是否相等 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 相等,跳出循环 break; // 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表 p = e; } } // 表示在桶中找到key值、hash值与插入元素相等的结点 if (e != null) { // 记录e的value V oldValue = e.value; // onlyIfAbsent为false或者旧值为null if (!onlyIfAbsent || oldValue == null) //用新值替换旧值 e.value = value; // 访问后回调 afterNodeAccess(e); // 返回旧值 return oldValue; } } // 结构性修改 ++modCount; // 实际大小大于阈值则扩容 if (++size > threshold) resize(); // 插入后回调 afterNodeInsertion(evict); return null; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 数组元素相等 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; // 桶中不止一个节点 if ((e = first.next) != null) { // 在树中get if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 在链表中get do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { // 超过最大值就不再扩充了,就只好随你碰撞去吧 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 没超过最大值,就扩充为原来的2倍 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // 计算新的resize上限 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { // 把每个bucket都移动到新的buckets中 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; // 原索引 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } // 原索引+oldCap else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // 原索引放到bucket里 if (loTail != null) { loTail.next = null; newTab[j] = loHead; } // 原索引+oldCap放到bucket里 if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
-
HashMap的容量为什么是2的n次幂?
https://blog.csdn.net/sybnfkn040601/article/details/73194613
用
h & (length - 1)取代h % length,位运算取低位速度快。 -
hashmap hash算法的具体实现,巧妙之处
-
hashmap规定长度必定为2的n次方、如果指定的capacity不为2的n次方,会将其转换为>capacity的最小的2的次方数
-
hash算法 hash = h ^ (h »> 16),保证了capacity较小时,能够将高16位和低16位的变化都反应到低位上,在计算下标时,高位和地位同时参与,使hash更加均匀分散,降低hash碰撞的概率
-
put的时候会put到table[(n-1)&hash],因为n为2的n次方,所以n-1导致低位全是1,便可以保证hash与上n-1得到的数组下标一定在0~n-1之间
-
get的时候依然是直接用table[(n-1)&hash]
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
1 2 3 4 5 6 7
static final int hash(Object key) { int h; // key.hashCode():返回散列值也就是hashcode // ^ :按位异或 // >>>:无符号右移,忽略符号位,空位都以0补齐 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
-
-
hashmap扩容resize怎么实现
1、首先建立新数组newTable、为原数组的两倍
2、将原数组hash到新数组中,hash & (newLength-1) ,
3、如果原数组节点只有一个头节点,则hash到新数组直接放入
4、如果原数组e是树节点,则将其split(保持顺序分裂成两个树节点TreeNode list、list过长则转化成树,不然则彻底转成node list)
5、如果是链表,则保持原数组中链表的顺序,hash到新数组中
https://segmentfault.com/a/1190000015812438?utm_source=tag-newest
-
hashmap扩容时每个entry需要再计算一次hash吗?
还是原来的hash,
hash & oldCap如果是0的话就是原索引,否则是原索引+oldCap -
jdk1.8之前并发操作hashmap时为什么会有死循环的问题
在并发的情况,发生扩容时,可能会产生循环链表,在执行get的时候,会触发死循环,引起CPU的100%问题,所以一定要避免在并发环境下使用HashMap。
Java 8虽然修复了死循环的BUG,但是HashMap 还是非线程安全类,仍然会产生数据丢失等问题。
-
hashmap一个写,多个读并发会有线程安全问题吗,引申出fail-fast和iterator
1、会导致数据读写不一致的问题、因为JMM(java内存模型)里线程只能先与自己的工作内存交互,之后才能与共享内存交互
2、会导致fail-fast问题(这是java集合的一个错误检测机制)
fail-fast:如果在集合迭代的过程中,iterator(迭代器)不知道集合发生了修改(add/remove)操作,就会报错
如何实现遍历集合的同时进行修改:让iterator知道,即用iterator自带的remove方法:iterator.remove();
modCount是集合通用的属性,只要集合发生了修改操作,modCount就会++,在获取迭代器的时候会将modCount赋值给ExpectedModCount,此时两者肯定相等,但是如果执行了修改操作,modCound就会++,两者不等,就会报错。
- 场景1:写线程唯一、读线程不确定,没有迭代操作。使用hashmap不会存在程序不安全,最多就是发生数据不一致性的问题。
- 场景2:写线程唯一、读线程不确定,有迭代操作,此时不能使用hashmap,会存在fastfail问题
- 场景3: 读写线程是同一个,且唯一,有迭代操作,此时注意不能通过集合方法remove或者add更改,只能通过iterator内方法来更新。不然会存在fastfail问题。
-
==和equals()的区别
- ==:判断两个对象的地址是不是相等。
- equals()
- 情况1:类没有覆盖equals()方法时,等价于==。
- 情况2:覆盖类equals()方法,来比较两个对象的内容是否相等。
-
hashCode()和equals()的区别
- hashCode()的作用:获取散列码,实际上是一个int整数。
- 为什么要有散列码?以“HashSet”如何检查重复为例:当把对象加入HashSet时,HashSet会先计算散列码,如果没有相符的散列码,HashSet会假设对象没有重复出现,如果发现有相同散列码的对象,会调用equals()方法来检查对象是否真的相同。如果两者相同,HashSet就不会让它加入,否则就会重新散列到其他位置。这样就大大减少equals()的次数,提高执行速度。
- 相关规定
- 如果两个对象相等,则散列码相同。
- 如果两个对象相等,则两个对象分别调用equals()方法都返回true。
- 两个对象有相同的散列码,它们也不一定是相等的。
- equals()方法被覆盖过,则hashCode()方法也必须被覆盖。
- hashCode()的默认行为是对堆上的对象产生独特值,如果没有重写hashcode(),则同一个类的两个对象无论如何不会相等。
-
重写equals()是否需要重写hashcode(),不重写会有什么后果
需要,不重写有可能两个对象相等但是hashcode不相等,HashMap中存在重复的键。
-
HashMap的key可以是可变的对象吗
运行时可能会出现找不到key的问题。
-
如果hashMap的key是一个自定义的类,怎么办?
使用HashMap,如果key是自定义的类,就必须重写hashcode()和equals()。
-
TreeMap的底层实现
-
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点。
红黑树的插入、删除、遍历时间复杂度都为O(lgN),所以性能上低于哈希表。但是哈希表无法提供键值对的有序输出,红黑树因为是排序插入的,可以按照键的值的大小有序输出。
-
红黑树性质:
性质1:每个节点要么是红色,要么是黑色。
性质2:根节点永远是黑色的。
性质3:所有的叶节点都是空节点(即 null),并且是黑色的。
性质4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
性质5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
-
-
红黑树和平衡二叉树的区别、java中哪种数据结构实现了红黑树
BST:二叉搜索树、不确保平衡、性能无法确保
AVL:平衡二叉树,严格平衡(每个节点的左右子树的高度差不超过1),搜索性能可以一直确保最佳,但是一旦有插入删除操作,就必须 要进行旋转,来维持树的严格平衡,而旋转操作是非常耗时的。所以AVL使用于搜索操作多,而插入删除操作少的场景
RBT:红黑树,弱平衡(红黑树确保没有一条路径会比其他路径长出两倍),这样子的话一旦有插入删除操作,用于维持RBT规则的旋转操作次数就会很少。用非严格的平衡来换取增删节点时候旋转次数的降低。所以RBT适用于插入删除操作多的场景
所以简单说,搜索的次数远远大于插入和删除,那么选择AVL树,如果搜索,插入删除次数几乎差不多,应该选择RB树
java的TreeMap实现了红黑树
-
类型擦除
泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。
-
String为什么是不可变的
- 用不可变类型做HashMap和HashSet键值。
- 不可变对象不能被写,所以线程安全。
String one = "someString";使用字符串常量池,在大量使用字符串的情况下,可以节省内存空间,提高效率。
-
多态的实现原理
-
Java 的方法调用方式
Java 的方法调用有两类,动态方法调用与静态方法调用。
静态方法调用是指对于类的静态方法的调用方式,是静态绑定的;而动态方法调用需要有方法调用所作用的对象,是动态绑定的。
类调用 (invokestatic) 是在编译时就已经确定好具体调用方法的情况。
实例调用 (invokevirtual)则是在调用的时候才确定具体的调用方法,这就是动态绑定,也是多态要解决的核心问题。
-
方法重写后的动态绑定
方法表是实现动态调用的核心。为了优化对象调用方法的速度,方法区的类型信息会增加一个指针,该指针指向记录该类方法的方法表,方法表中的每一个项都是对应方法的指针。这些方法中包括从父类继承的所有方法以及自身重写(override)的方法。
多态允许具体访问时实现方法的动态绑定。Java对于动态绑定的实现主要依赖于方法表,通过继承和接口的多态实现有所不同。
继承:在执行某个方法时,在方法区中找到该类的方法表,再确认该方法在方法表中的偏移量,找到该方法后如果被重写则直接调用,否则认为没有重写父类该方法,这时会按照继承关系搜索父类的方法表中该偏移量对应的方法。
接口:Java 允许一个类实现多个接口,从某种意义上来说相当于多继承,这样同一个接口的的方法在不同类方法表中的位置就可能不一样了。所以不能通过偏移量的方法,而是通过搜索完整的方法表。
-
-
ArrayList如何扩容和缩容
1、扩容:直接是采用底层的System.copyOf(),创建一个新的大数组,将原来的数组内容copy到新数组中,然后返回新数组的引用
2、缩容:trimToSize()。如果实际size<数组长度,在内存紧张的情况下,会将数组缩小,采用的依然是System.copyOf()
-
如何用LinkedHashMap实现LRU?
LinkedHashMap重写removeEldestEntry()方法,当前size()大于了cacheSize便删掉头部的元素
-
如何用TreeMap实现一致性hash?
什么是一致性hash
自己实现一个一致性 Hash 算法
- 内部没有使用数组,而是使用了有序 Map。
- put 方法中,对象如果没有落到缓存节点上,就找比他小的节点且离他最近的。这里我们使用了 TreeMap 的 tailMap 方法,具体 API 可以看文档。
- get 方法中,和 put 步骤相同,否则是取不到对象的。
-
HashMap和HashSet的区别
-
HashSet 底层就是基于 HashMap 实现的。
-
HashMap HashSet 实现了Map接口 实现Set接口 存储键值对 仅存储对象 调用 put()向map中添加元素调用 add()方法向Set中添加元素HashMap使用键(Key)计算Hashcode HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性
-
Java8
lambda表达式、方法引用、stream、optional、接口中的默认方法、函数式接口
https://snailclimb.gitee.io/javaguide/#/docs/java/What’s%20New%20in%20JDK8/Java8Tutorial
- Lambda 表达式:Lambda允许把函数作为一个方法的参数
- 方法和构造函数引用
- 接口的默认方法
- 函数式接口,内置函数式接口(Predicate, Function, Supplier, Consumer, Comparator)
- Stream
Java8 新增了非常多的特性,我们主要讨论以下几个:
Lambda 表达式 − Lambda 允许把函数作为一个方法的参数(函数作为参数传递到方法中)。
方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
Date Time API − 加强对日期与时间的处理。
Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
Java代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
String.valueOf(i)
String s = "Hello world";
System.out.println(s.indexOf("world"));
System.out.println(s.substring(0, 5));
System.out.println(s.replace("Hello", "Hi"));
System.out.println(Arrays.asList(s.split(" ")));
StringBuffer str = new StringBuffer(s);
str.append("!");
System.out.println(str);
str.setCharAt(0)
str.setLength(10)
str.toString()
int[][] arr = new int[3][4];
int[][] arr = \{\{1,2},{3,4,5,6},{7,8,9\}\};
arr[0].length
Arrays.fill(array, 100);
Arrays.fill(array, startIndex, endIndex, 100);
String a[] = { "A", "E", "I" };
String b[] = { "O", "U" };
List list = new ArrayList(Arrays.asList(a));
list.addAll(Arrays.asList(b));
Object[] c = list.toArray();
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(5);
arrayList.add(index, 5);
arrayList.remove(index);
arrayList.contains(5);
arrayList.indexOf(5);
Collections.sort(arrayList);
Collections.shuffle(arrayList);
Collections.swap(arrayList, index, index);
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
Collections.max(arrayList)
Collections.min(arrayList)
Collections.binarySearch(arrayList, 7)
class Student implements Comparable {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Object o) {
return age - ((Student) o).age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class Main {
public static void main(String[] args) {
ArrayList<Student> arrayList = new ArrayList<>();
arrayList.add(new Student("2", 2));
arrayList.add(new Student("1", 1));
Collections.sort(arrayList, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.compareTo(o1);
}
});
System.out.println(arrayList);
}
}
LinkedList<Integer> linkedList = new LinkedList<>();
Queue<Integer> linkedList = new LinkedList<>();
Stack<Integer> linkedList = new Stack<>();
// array: add - remove
linkedList.add(1);
linkedList.add(index, 1);
linkedList.addFirst(1);
linkedList.addLast(1);
// queue: offer - poll
linkedList.offer(6);
linkedList.offerFirst(4);
linkedList.offerLast(4);
// stack: push - pop
linkedList.push(7);
linkedList.pop();
linkedList.peek();
//Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。 如果要使用前端而不移出该元素,使用element()或者peek()方法。
// 小根堆
Queue<Integer> queue = new PriorityQueue<>();
// 大根堆
Queue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
queue.offer(1);
queue.offer(2);
queue.offer(3);
System.out.println(queue.peek());
queue.poll();
System.out.println(queue);
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("1", "1st");
hashMap.put("2", "2nd");
Collection cl = hashMap.keySet();
Collection cl = hashMap.values();
Iterator it = cl.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
HashSet<String> hashSet = new HashSet<>();
hashSet.add("yellow");
hashSet.add("white");
Iterator it = hashSet.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
for(String s: hashSet) {
System.out.println(s);
}
try {
BufferedWriter out = new BufferedWriter(new FileWriter("f.txt"));
out.write("Hello world\n");
out.write("Hello world\n");
out.close();
} catch (IOException e) {
}
try {
BufferedReader in = new BufferedReader(new FileReader("f.txt"));
String str;
while((str = in.readLine()) != null) {
System.out.println(str);
}
} catch (IOException e) {
}
Random random = new Random();
System.out.println(random.nextLong());
System.out.println(random.nextInt(100));
-
Collections、Arrays工具类
-
Collections
-
排序
1 2 3 4 5 6
void reverse(List list)//反转 void shuffle(List list)//随机排序 void sort(List list)//按自然排序的升序排序 void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑 void swap(List list, int i , int j)//交换两个索引位置的元素 void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
实例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
ArrayList<Integer> arrayList = new ArrayList<Integer>(); arrayList.add(-1); arrayList.add(3); arrayList.add(3); arrayList.add(-5); arrayList.add(7); arrayList.add(4); arrayList.add(-9); arrayList.add(-7); System.out.println("原始数组:"); System.out.println(arrayList); // void reverse(List list):反转 Collections.reverse(arrayList); System.out.println("Collections.reverse(arrayList):"); System.out.println(arrayList); Collections.rotate(arrayList, 4); System.out.println("Collections.rotate(arrayList, 4):"); System.out.println(arrayList); // void sort(List list),按自然排序的升序排序 Collections.sort(arrayList); System.out.println("Collections.sort(arrayList):"); System.out.println(arrayList); // void shuffle(List list),随机排序 Collections.shuffle(arrayList); System.out.println("Collections.shuffle(arrayList):"); System.out.println(arrayList); // void swap(List list, int i , int j),交换两个索引位置的元素 Collections.swap(arrayList, 2, 5); System.out.println("Collections.swap(arrayList, 2, 5):"); System.out.println(arrayList); // 定制排序的用法 Collections.sort(arrayList, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2.compareTo(o1); } }); System.out.println("定制排序后:"); System.out.println(arrayList);
-
查找、替换
1 2 3 4 5 6 7
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的 int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll) int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c) void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。 int frequency(Collection c, Object o)//统计元素出现次数 int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target). boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
ArrayList<Integer> arrayList = new ArrayList<Integer>(); arrayList.add(-1); arrayList.add(3); arrayList.add(3); arrayList.add(-5); arrayList.add(7); arrayList.add(4); arrayList.add(-9); arrayList.add(-7); ArrayList<Integer> arrayList2 = new ArrayList<Integer>(); arrayList2.add(-3); arrayList2.add(-5); arrayList2.add(7); System.out.println("原始数组:"); System.out.println(arrayList); System.out.println("Collections.max(arrayList):"); System.out.println(Collections.max(arrayList)); System.out.println("Collections.min(arrayList):"); System.out.println(Collections.min(arrayList)); System.out.println("Collections.replaceAll(arrayList, 3, -3):"); Collections.replaceAll(arrayList, 3, -3); System.out.println(arrayList); System.out.println("Collections.frequency(arrayList, -3):"); System.out.println(Collections.frequency(arrayList, -3)); System.out.println("Collections.indexOfSubList(arrayList, arrayList2):"); System.out.println(Collections.indexOfSubList(arrayList, arrayList2)); System.out.println("Collections.binarySearch(arrayList, 7):"); // 对List进行二分查找,返回索引,List必须是有序的 Collections.sort(arrayList); System.out.println(Collections.binarySearch(arrayList, 7));
-
同步控制
效率非常低
-
-
Arrays
- 排序 :
sort() - 查找 :
binarySearch() - 比较:
equals() - 填充 :
fill() - 转列表:
asList() - 转字符串 :
toString() - 复制:
copyOf()
- 排序 :
-
-
Comparable和Comparator接口的作用以及它们的区别
-
Java提供了只包含一个compareTo()方法的Comparable接口。这个方法可以个给两个对象排序。具体来说,它返回负数,0,正数来表明输入对象小于,等于,大于已经存在的对象。
-
Java提供了包含compare()和equals()两个方法的Comparator接口。compare()方法用来给两个输入参数排序,返回负数,0,正数表明第一个参数是小于,等于,大于第二个参数。equals()方法需要一个对象作为参数,它用来决定输入参数是否和comparator相等。只有当输入参数也是一个comparator并且输入参数和当前comparator的排序结果是相同的时候,这个方法才返回true。
-
Comparable接口的实现是在类的内部(如 String、Integer已经实现了Comparable接口,自己就可以完成比较大小操作),Comparator接口的实现是在类的外部(可以理解为一个是自已完成比较,一个是外部程序实现比较)
-
实现Comparable接口要重写compareTo方法, 在compareTo方法里面实现比较
1 2 3 4 5 6 7 8 9 10 11 12 13
public class Student implements Comparable { String name; int age public int compareTo(Student another) { int i = 0; i = name.compareTo(another.name); if(i == 0) { return age - another.age; } else { return i; } } }
这时我们可以直接用 Collections.sort( StudentList ) 对其排序了(只需传入要排序的列表)
-
实现Comparator需要重写 compare 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public class Student{ String name; int age } class StudentComparator implements Comparator { public int compare(Student one, Student another) { int i = 0; i = one.name.compareTo(another.name); if(i == 0) { return one.age - another.age; } else { return i; } } }
Collections.sort( StudentList , new StudentComparator()) 可以对其排序(不仅要传入待排序的列表,还要传入实现了Comparator的类的对象)
-
java 8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
import java.util.*;
import java.util.concurrent.TimeUnit;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.function.Supplier;
interface Formula {
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
class Something {
String startsWith(String s) {
return String.valueOf(s.charAt(0));
}
}
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}
class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72;
return String.valueOf(from);
};
}
}
public class Main {
public static void main(String[] args) {
// 允许在接口中有默认方法实现
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
System.out.println(formula.calculate(100));
System.out.println(formula.sqrt(16));
// Lambda表达式
List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
// names.sort(new Comparator<String>() {
// @Override
// public int compare(String o1, String o2) {
// return o2.compareTo(o1);
// }
// });
names.sort((a, b) -> b.compareTo(a));
System.out.println(names);
// 函数式接口
// Converter<String, Integer> converter = from -> Integer.valueOf(from);
// Integer converted = converter.convert("123");
// System.out.println(converted);
// 方法和构造函数引用
// Converter<String, Integer> converter = Integer::valueOf;
// Integer converted = converter.convert("123");
// System.out.println(converted);
Something something = new Something();
Converter<String, String> converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted);
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");
// Lambda 表达式作用域
// final int num = 1;
// Converter<Integer, String> stringConverter =
// (from) -> String.valueOf(from + num);
// System.out.println(stringConverter.convert(2));
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
System.out.println(stringConverter.convert(2));
// 内置函数式接口
// Predicates
Predicate<String> predicate = (s) -> s.length() > 0;
System.out.println(predicate.test("foo"));
System.out.println(predicate.negate().test("foo"));
Predicate<Boolean> nonNull = Objects::nonNull;
Predicate<Boolean> isNull = Objects::isNull;
Predicate<String> isEmpty = String::isEmpty;
Predicate<String> isNotEmpty = isEmpty.negate();
// Functions
Function<String, Integer> toInteger = Integer::valueOf;
Function<String, String> backToString = toInteger.andThen(String::valueOf);
System.out.println(backToString.apply("123"));
// Suppliers
Supplier<Person> personSupplier = Person::new;
System.out.println(personSupplier.get());
// Consumers
Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));
// Comparators
Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
Person p1 = new Person("John", "Doe");
Person p2 = new Person("Alice", "Wonderland");
System.out.println(comparator.compare(p1, p2));
System.out.println(comparator.reversed().compare(p1, p2));
// Optionals
Optional<String> optional = Optional.of("bam");
System.out.println(optional.isPresent());
System.out.println(optional.get());
System.out.println(optional.orElse("fallback"));
optional.ifPresent((s) -> System.out.println(s.charAt(0)));
// Streams
List<String> stringCollection = new ArrayList<>();
stringCollection.add("ddd2");
stringCollection.add("aaa2");
stringCollection.add("bbb1");
stringCollection.add("aaa1");
stringCollection.add("bbb3");
stringCollection.add("ccc");
stringCollection.add("bbb2");
stringCollection.add("ddd1");
// Filter
stringCollection
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// Sorted
stringCollection
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// Map
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
// Match
boolean anyStartsWithA =
stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA =
stringCollection
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ =
stringCollection
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true
// Count
long startsWithB =
stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3
// Reduce
Optional<String> reduced =
stringCollection
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);
// "aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2"
// Parallel Streams
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}
// 顺序排序
// long t0 = System.nanoTime();
//
// long count = values.stream().sorted().count();
// System.out.println(count);
//
// long t1 = System.nanoTime();
//
// long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
// System.out.println(String.format("sequential sort took: %d ms", millis));
// sequential sort took: 899 ms
// 并行排序
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
// parallel sort took: 472 ms
// Map
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((id, val) -> System.out.println(val));
map.computeIfPresent(3, (number, val) -> val + number);
System.out.println(map.get(3)); // val33
map.computeIfPresent(9, (number, val) -> null);
System.out.println(map.containsKey(9)); // false
map.computeIfAbsent(23, number -> "val" + number);
System.out.println(map.containsKey(23)); // true
map.computeIfAbsent(3, number -> "bam");
System.out.println(map.get(3)); // val33
map.remove(3, "val3");
System.out.println(map.get(3)); // val33
map.remove(3, "val33");
System.out.println(map.get(3)); // null
System.out.println(map.getOrDefault(42, "not found")); // not found
map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
System.out.println(map.get(9)); // val9
map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
System.out.println(map.get(9)); // val9concat
}
}