后端
项目介绍
我负责智能执法平台里用户授权的工作,从用户查询到他所拥有的权限,开发接口管理用户角色、角色、权限的增删改查,和它们之间的多对多关系的增删改查。另外我还负责法规的检索和推荐的工作。
项目的问题
解决检索项目在服务器不能正常运行的问题
(1) 页面的搜索结果不能正常显示,但是后台并没有报错。
(2) 直接运行flask项目中的入口python文件没有问题,用uwsgi将配置文件中的3行多线程相关的内容注释掉也可以正常运行。
(3) 定位发现是调用HanLP的函数过程中线程会卡住。原因是利用python的jpype调用Hanlp的java源代码时,不能为新开启的线程分配JVM。解决方法是在每个API的开头添加两行代码,判断并为线程分配JVM。
项目怎么优化
https://tieba.baidu.com/p/6239499571?red_tag=0442800574&traceid=
redis缓存,异步,接口调优,SQL调优,调用超时
可以说一下分布式方面的改进吧,什么集群,数据库主从分离等等
Shiro
-
应用安全的四大基石
认证:用户身份识别,通常被称为用户“登录”。
授权:访问控制。比如某个用户是否具有某个操作的使用权限。
会话管理:特定于用户的会话管理,甚至在非web 或 EJB 应用程序。
加密:在对数据源使用加密算法加密的同时,保证易于使用。
-
三个主要的理念
Subject:当前用户,Subject 可以是一个人,但也可以是第三方服务、守护进程帐户、时钟守护任务或者其它–当前和软件交互的任何事件。
SecurityManager:管理所有Subject,SecurityManager 是 Shiro 架构的核心,配合内部安全组件共同组成安全伞。
Realms:用于进行权限信息的验证,我们自己实现。Realm 本质上是一个特定的安全 DAO:它封装与数据源连接的细节,得到Shiro 所需的相关的数据。在配置 Shiro 的时候,你必须指定至少一个Realm 来实现认证(authentication)和/或授权(authorization)。
-
Shiro 加密
在之前的学习中,我们在数据库中保存的密码都是明文的,一旦数据库数据泄露,那就会造成不可估算的损失,所以我们通常都会使用非对称加密,简单理解也就是不可逆的加密,而 md5 加密算法就是符合这样的一种算法。
如上面的 123456 用 Md5 加密后,得到的字符串:e10adc3949ba59abbe56e057f20f883e,就无法通过计算还原回 123456,我们把这个加密的字符串保存在数据库中,等下次用户登录时我们把密码通过同样的算法加密后再从数据库中取出这个字符串进行比较,就能够知道密码是否正确了,这样既保留了密码验证的功能又大大增加了安全性,但是问题是:虽然无法直接通过计算反推回密码,但是我们仍然可以通过计算一些简单的密码加密后的 Md5 值进行比较,推算出原来的密码
比如我的密码是 123456,你的密码也是,通过 md5 加密之后的字符串一致,所以你也就能知道我的密码了,如果我们把常用的一些密码都做 md5 加密得到一本字典,那么就可以得到相当一部分的人密码,这也就相当于“破解”了一样,所以其实也没有我们想象中的那么“安全”。
既然相同的密码 md5 一样,那么我们就让我们的原始密码再加一个随机数,然后再进行 md5 加密,这个随机数就是我们说的盐(salt),这样处理下来就能得到不同的 Md5 值,当然我们需要把这个随机数盐也保存进数据库中,以便我们进行验证。
另外我们可以通过多次加密的方法,即使黑客通过一定的技术手段拿到了我们的密码 md5 值,但它并不知道我们到底加密了多少次,所以这也使得破解工作变得艰难。
SpringBoot
-
SpringBoot介绍
我们知道Spring是重量级企业开发框架 Enterprise JavaBean(EJB) 的替代品,Spring为企业级Java开发提供了一种相对简单的方法,通过 依赖注入 和 面向切面编程 ,用简单的 Java对象(Plain Old Java Object,POJO) 实现了EJB的功能
虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置) 。Spring 2.5引入了基于注解的组件扫描,这消除了大量针对应用程序自身组件的显式XML配置。Spring 3.0引入了基于Java的配置,这是一种类型安全的可重构配置方式,可以代替XML。
尽管如此,我们依旧没能逃脱配置的魔爪。开启某些Spring特性时,比如事务管理和Spring MVC,还是需要用XML或Java进行显式配置。启用第三方库时也需要显式配置,比如基于Thymeleaf的Web视图。配置Servlet和过滤器(比如Spring的DispatcherServlet)同样需要在web.xml或Servlet初始化代码里进行显式配置。组件扫描减少了配置量,Java配置让它看上去简洁不少,但Spring还是需要不少配置。
光配置这些XML文件都够我们头疼的了,占用了我们大部分时间和精力。除此之外,相关库的依赖非常让人头疼,不同库之间的版本冲突也非常常见。
从本质上来说,Spring Boot就是Spring,它做了那些没有它你自己也会去做的Spring Bean配置。
-
Spring Boot 项目结构分析
- Application.java是项目的启动类
- domain目录主要用于实体(Entity)与数据访问层(Repository)
- service 层主要是业务类代码
- controller 负责页面访问控制
- config 目录主要放一些配置类
-
开发 RestFul Web 服务
RESTful Web 服务介绍
RESTful Web 服务与传统的 MVC 开发一个关键区别是返回给客户端的内容的创建方式:传统的 MVC 模式开发会直接返回给客户端一个视图,但是 RESTful Web 服务一般会将返回的数据以 JSON 的形式返回,这也就是现在所推崇的前后端分离开发。
@RestController将返回的对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中。 绝大部分情况下都是直接以 JSON 形式返回给客户端,很少的情况下才会以 XML 形式返回。转换成 XML 形式还需要额为的工作,上面代码中演示的直接就是将对象数据直接以 JSON 形式写入 HTTP 响应(Response)中。关于@Controller和@RestController 的对比,我会在下一篇文章中单独介绍到(@Controller +@ResponseBody= @RestController)。@RequestMapping:上面的示例中没有指定 GET 与 PUT、POST 等,因为@RequestMapping默认映射所有HTTP Action,你可以使用@RequestMapping(method=ActionType)来缩小这个映射。@PostMapping实际上就等价于 @RequestMapping(method = RequestMethod.POST),同样的 @DeleteMapping ,@GetMapping也都一样,常用的 HTTP Action 都有一个这种形式的注解所对应。@PathVariable:取url地址中的参数。@RequestParam url的查询参数值。@RequestBody:可以将 HttpRequest body 中的 JSON 类型数据反序列化为合适的 Java 类型。- ResponseEntity: 表示整个HTTP Response:状态码,标头和正文内容。我们可以使用它来自定义HTTP Response 的内容。
@RestController=@Controller+@ResponseBody@RequestMapping,@PostMapping,@GetMapping@RequestBody,@RequestParam -
Spring Boot JPA 基础:常见操作解析
https://github.com/Snailclimb/springboot-guide/blob/master/docs/basis/springboot-jpa.md
实体类:为这个类添加了 @Entity 注解代表它是数据库持久化类
创建操作数据库的 Repository 接口:首先这个接口加了 @Repository 注解,代表它和数据库操作有关。另外,它继承了 JpaRepository<Person, Long>接口
-
JPA 中非常重要的连表查询就是这么简单
https://github.com/Snailclimb/springboot-guide/blob/master/docs/basis/springboot-jpa-lianbiao.md
连表查询
我们需要创建一个包含我们需要的 Person 信息的 DTO 对象,我们简单第将其命名为 UserDTO,用于保存和传输我们想要的信息。
sql 语句和我们平时写的没啥区别,差别比较大的就是里面有一个 new 对象的操作。
分页操作
为了实现分页,我们在@Query注解中还添加了 countQuery 属性。
传入Pageable pageable,返回Page
Maven
https://blog.csdn.net/weixin_37766296/article/details/79594837
优点
- Maven是一个项目管理和综合工具。Maven提供了开发人员构建一个完整的生命周期框架。
- 在多个开发团队环境时,Maven可以设置按标准在非常短的时间里完成配置工作,使开发人员的工作更加轻松。
- Maven增加可重用性并负责建立相关的任务。
Maven常用命令
clean:删除项目中已经编译好的信息,删除target目录
compile:Maven工程的编译命令,用于编译项目的源代码,将src/main/java下的文件编译成class文件输出到target目录下。
test:使用合适的单元测试框架运行测试。
package:将编译好的代码打包成可分发的格式,如JAR,WAR。
install:安装包至本地仓库,以备本地的其它项目作为依赖使用。
deploy:复制最终的包至远程仓库,共享给其它开发人员和项目(通常和一次正式的发布相关)。
每一个构建项目的命令都对应了maven底层一个插件。
Maven命令package、install、deploy的联系与区别
mvn clean package依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)等7个阶段。
mvn clean install依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install等8个阶段。
mvn clean deploy依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install、deploy等9个阶段。
主要区别:
package命令完成了项目编译、单元测试、打包功能,但没有把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库。
install命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库,但没有布署到远程maven私服仓库。
deploy命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库。
Maven生命周期
清理生命周期:运行mvn clean将调用清理生命周期 。
默认生命周期:是一个软件应用程序构建过程的总体模型 。
compile,test,package,install,deploy
站点生命周期:为一个或者一组项目生成项目文档和报告,使用较少。
大数据
大数据课程PPT摘录
(1) 大数据分析系统层次结构
应用层
算法层:应用算法层(排名与推荐、图像分析、文本分析、Web挖掘与检索)、基础算法层(ML、DL)
系统软件层:计算框架(Mapreduce、Spark、Storm)、数据管理(NoSQL、Hbase、GFS、BigTable)
基础设施层:GPU、Hadoop、IaaS/PaaS
(2) 面向大数据的文件系统 - HDFS
1) 主节点也叫名称节点,从节点也叫数据节点。
2) HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位。
3) 在HDFS中,名称节点负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog:FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据,操作日志文件EditLog中记录了所有针对文件创建、删除、重命名等操作。
4) HDFS常用命令
hadoop fs -mkdir
hadoop fs -ls
hadoop fs -copyFromLocal
hadoop fs -cat
5) HDFS数据读写Java接口
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path(uri));
FSDataOutputStream out = fs.create(new Path(uri));
(3) 大数据计算-Mapreduce
1) MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。
2) MapReduce体系结构
Client:用户编写的MapReduce程序通过Client提交到JobTracker,用户可通过Client提供的一些接口查看作业运行状态
JobTracker:JobTracker负责资源监控和作业调度
TaskTracker:TaskTracker会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
Task:Task分为Map Task和Reduce Task两种,均由TaskTracker启动。
(4) 大数据计算 - Spark
1) MapReduce框架把中间结果写入到HDFS中,RDD是Spark中对数据和计算的抽象。
2) RDD的数据运算包括动作和转换,转换操作是从一个或多个RDD生成新的RDD,动作操作是从RDD生成最后的计算结果。转换是惰性的,只有动作发生时才真正进行计算。
3) RDD的依赖关系构成有向无环图,依赖关系分为窄依赖和宽依赖。得到DAG后,Spark根据DAG中RDD的宽依赖关系将计算划分为多个任务集,也就是Stage。
(5) 面向大数据的数据库系统
1) NoSQL的四大类型:键值数据库(Redis)、列族数据库(BigTable, HBase)、文档数据库(MongoDB)、图形数据库(Neo4j)。
2) CAP:一致性、可用性、分区容忍性
关系型数据库的ACID:原子性、一致性、隔离性、持久性
BASE:基本可用性、软状态、最终一致性
3) HBase把数据存储为未经解释的字符串,数据模型简单;只有简单的插入、查询、删除、清空操作,不存在表与表之间的关系;基于列存储,不同列族文件分离;只有行键索引;更新操作后旧的版本仍然保留。
4) HBase包括客户端、一个主服务器、许多个Region服务器。Zookeeper文件记录-ROOT-表的位置信息,-ROOT-表记录.META.表的Region位置信息,.META.表记录用户数据表的Region位置信息。
(6) 流计算 - Storm
1) Storm将数据流Stream描述为无限的Tuple序列,每个Stream的源头抽象为Spout,将Stream的状态转换抽象为Bolt,将Spouts和Bolts组成的网络抽象成Topolog。
2) Storm集群采用Master-Slave架构,使用Zookeeper作为分布式协调组件。
大数据分析平台的构建方法
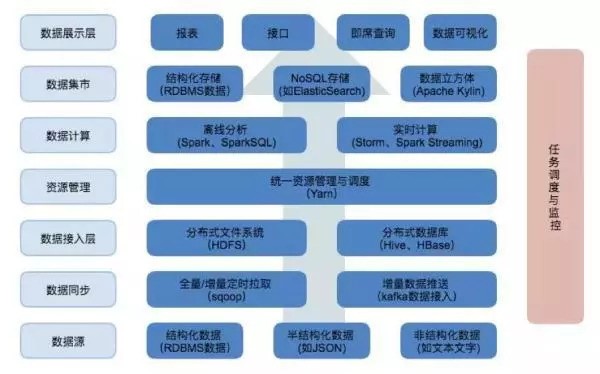
1.数据存储
1
2
3
4
5
6
7
基于Hadoop的数据湖主要用到了HDFS、Hive和HBase,HDFS是Hadoop平台的文件存储系统,我们直接操纵文件是比较复杂的,所以可以使用分布式数据库Hive或HBase用来做数据湖,存储接入层、数据仓库、数据集市的数据。
Hive和HBase各有优势:HBase是一个NoSQL数据库,随机查询性能和可扩展性都比较好;而Hive是一个基于HDFS的数据库,数据文件都以HDFS文件(夹)形式存放,存储了表的存储位置(即在HDFS中的位置)、存储格式等元数据,Hive支持SQL查询,可将查询解析成Map/Reduce执行,这对传统的数据分析平台开发人员更友好。
Hive数据格式可选择文本格式或二进制格式,文本格式有csv、json或自定义分隔,二进制格式有orc或parquet,他们都基于行列式存储,在查询时性能更好。同时可选择分区(partition),这样在查询时可通过条件过滤进一步减少数据量。接入层一般选择csv或json等文本格式,也不做分区,以尽量简化数据同步。数据仓库则选择orc或parquet,以提升数据离线计算性能。
数据集市这块可以选择将进行分析后的结果数据同步至传统数据库(RDBMS),也可以停留在大数据分析平台,使用NoSQL提供数据查询或用Apache Kylin来构建数据立方体,提供SQL查询接口。
2.数据同步
1
2
3
我们通过数据同步功能使得数据到达接入层,使用到了Sqoop和Kafka。数据同步可以分为全量同步和增量同步,对于小表可以采用全量同步,对于大表全量同步是比较耗时的,一般都采用增量同步,将变动同步到数据平台执行,以达到两边数据一致的目的。
全量同步使用Sqoop数据同步组件来完成,增量同步如果考虑定时执行,也可以用Sqoop来完成。或者,也可以通过Kafka等MQ流式同步数据,前提是外部数据源会将变动发送到MQ。
3.离线计算
1
2
3
我们使用Yarn来统一管理和调度计算资源。相较Map/Reduce,Spark SQL及Spark RDD对开发人员更友好,基于内存计算效率也更高,所以我们使用Spark on Yarn作为分析平台的计算选型。
ETL可以通过Spark SQL或Hive SQL来完成,Hive在2.0以后支持存储过程,使用起来更方便。当然,出于性能考虑Saprk SQL还是不错的选择。
4.数据可视化
1
对于处理得到的数据可以对接主流的BI系统,常见的BI系统包括Tableau、Superset。Superset数据可视化工具可以连接到Apache Kylin,Apache Kylin提供Hadoop/Spark之上的SQL查询接口。
5.参考
1
2
3
4
5
https://www.zhihu.com/question/35950209
https://blog.csdn.net/An342647823/article/details/87938091
https://www.cnblogs.com/davidwang456/articles/5340145.html
Scala
- set和map默认都是不可变的,如果声明可变集需要引入包。可变集和不可变集都有添加或删除元素的操作。对不可变集进行操作,会产生一个新的集,原来的集并不会发生变化, 而对可变集进行操作,改变的是该集本身。
- Python中,迭代器对象提供next方法。生成器自动实现迭代器,生成器函数使用yield返回结果,yield语句挂起该生成器函数的状态,在需要的时候才产生结果。将列表推导的中括号替换成圆括号,就是一个生成器表达式。scala中的for推导式采用yield关键字。 https://www.zhihu.com/question/24807364 https://www.runoob.com/python3/python3-iterator-generator.html
- 类中方法的写法。getter和setter方法。Scala的主构造器是整个类体,需要在类名称后面罗列出构造器所需的所有参数,可以有多个辅助构造器。
- Scala没有Java那样的静态方法或静态字段,可以采用object关键字实现单例对象,具备和Java静态方法同样的功能。在Java中,我们经常需要用到同时包含实例方法和静态方法的类,在Scala中可以通过伴生对象来实现。每个Scala应用程序都必须从一个对象的main方法开始。
- Scala中没有接口的概念,而是提供了“特质(trait)”。Java中接口中只能有抽象的方法,而Scala特质中的字段和方法不一定要是抽象的。
- Option类型,None或者Some。
- apply方法在给对象传参数的时候调用,update方法在给对象赋值时调用。伴生对象有一个重要用途,那就是,我们通常将伴生对象作为工厂使用,这样就不需要使用关键字new来创建一个实例化对象了。
- Scala中的函数式编程
http://dblab.xmu.edu.cn/blog/spark/
(1) 匿名函数又称为Lambda表达式,不需要给函数命名。函数只会引用函数中定义的变量,不会引用函数外部的变量,而闭包会引用函数外部的变量,每个闭包都会访问闭包创建时活跃的more变量。
(2) 高阶函数:接受函数参数的函数。
(3) 只要每个参数在函数字面量内仅出现一次,可以使用下划线作为一个或多个参数的占位符。
Spark
-
Spark的优点
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。使用Hadoop进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中间数据,IO开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
-
Spark RDD原理
1) MapReduce框架把中间结果写入到HDFS中,RDD是Spark中对数据和计算的抽象。
2) RDD的数据运算包括动作和转换,转换操作是从一个或多个RDD生成新的RDD,动作操作是从RDD生成最后的计算结果。转换是惰性的,只有动作发生时才真正进行计算。
3) RDD的依赖关系构成有向无环图,依赖关系分为窄依赖和宽依赖。得到DAG后,Spark根据DAG中RDD的宽依赖关系将计算划分为多个任务集,也就是Stage。
-
Spark RDD编程
1) 创建RDD
从文件系统中加载数据创建RDD: sc.textFile()
通过并行集合(数组)创建RDD: sc.parallelize()
2) RDD操作
转换操作:filter(func), map(func), flatMap(func), groupByKey(), reduceByKey(func)
行动操作:count(), collect(), first(), take(n), reduce(func), foreach(func)
键值对转换操作:reduceByKey(func), groupByKey(), keys, values, sortByKey(), mapValues(func), join()
3) 持久化
persist(), cache()
-
Spark DataFrame
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。
-
Spark Steaming
Spark Streaming是构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。
Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
算法
罚金预测的问题和解决方法
-
一般的深度学习模型是为了解决分类问题,而罚款金额预测是一个输出为连续值的回归问题。
网上的一些回答涉及到了这个问题。
https://www.zhihu.com/question/39792141
https://www.zhihu.com/question/59829734
https://www.zhihu.com/question/23346239
归纳起来有以下几点:
-
回归问题比分类问题更难用神经网络模型学习,原因是:
-
一是回归任务对目标的要求比较严苛,要预测值刚好等于真实值才会使得损失函数为0,而分类任务则宽松得多。
-
二则主要是优化方面的问题,如果使用了sigmoid/tanh等易饱和的激活函数,在使用softmax等分类任务的损失函数时一定程度上可以消除这种饱和影响,而回归任务使用的损失函数不具备这种能力。更进一步,回归任务的损失函数一般为MSE,反向传播中求导后可以看到梯度是与真实的lable成正比的,所以回归任务对于数据中的outlier十分敏感,训练数据中的噪声使得梯度波动很大甚至产生梯度爆炸,导致模型得不到有效训练。这是神经网络中回归任务难以训练的一个重要原因。
-
-
通过划分区间,把回归问题转换为分类问题,这样往往能取得更好的效果
-
根据图像预测年龄也是输出为连续值的回归问题
-
根据案例所触犯的法规、时间、地点、用户性质等因素预测罚款金额的问题,类似根据地段、房屋大小、厕所数目等因素预测房价的问题。详细描述在类似问题解决案例中。
-
-
每个案例中用户触犯法规的数目是不定长的,而深度学习模型需要输入张量。
-
方案一:将每个案例中用户触犯的法规进行独热编码,转换成一个 0-1 向量。由于规范用语各个专业加起来大概在几千条左右,每个专业一般在几百条左右,而每个案例中用户触犯的法规一般只有两三个,因此进行独热编码后的模型输入向量会很稀疏,向量中大量的 0 可能会对模型的运行结果造成影响。
-
方案二:参考文本序列输入长度不等的处理方法,用编号表示对应的法规,并做相应的补齐。
网上有一些相关的问题和回答。
https://www.zhihu.com/question/305508138/answer/550573253
https://www.zhihu.com/question/264501322/answer/282116408
https://www.zhihu.com/question/55014250
-
补 0 方案
有一种最简单的方案,将所有的样本,都用 0 补全到固定长度。比如,每个 minibatch 中有三个句子,全部做长度为 15 的补全:
1 2 3
tensor([[ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0], [ 12, 13, 14, 15, 16, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0], [ 17, 5, 18, 19, 20, 21, 22, 23, 24, 25, 5, 0, 0, 0, 0]])在计算 cost 时,再跳过将补全位置的值。对于翻译任务,attention 的 softmax 计算也要跳过这些位置。这种方案实现简单,但是为了和训练过程保持一致,预测解码也需要做补全。对于线上实时系统来说,对所有句子做补全,会大大降低处理速度。设想一下,将 “How are you ?” 这种短句做补全到 100,要多做25倍的迭代。
-
Mask 方案
在NLP中,一个常见的问题是输入序列长度不等,而mask可以帮助我们处理。虽然RNN等模型可以处理不定长的input,但是在实践中,需要对input做batchize,转换成固定大小的tensor,方便矩阵操作,常见的shape如下:(seq_len, batch_size, dim)。
举个例子:
case 1: I like cats.case 2: He does not like cats.假设默认的seq_len是5,一般会对case 1做pad处理,变成
1
I like cats <PAD> <PAD>
在上述例子数字编码后,开始做embedding,而pad也会有embedding向量,但pad本身没有实际意义,参与训练可能还是有害的。因此,有必要维护一个mask tensor来记录哪些是真实的value,上述例子的两个mask如下:
1 1 1 0 01 1 1 1 1后续再梯度传播中,mask起到了过滤的作用,在pytorch中,有参数可以设置:
nn.Embedding(vocab_size, embed_dim,padding_idx=0) -
为什么 RNN 需要 mask 输入,而 CNN 不需要?
对于RNN来说,如果不用mask而是补0的话,补0的位置也会参与状态向量的计算,用mask和补0相比,得到的状态向量是不一样的。因为RNN状态向量计算的时候不仅仅考虑了当前输入,也考虑了上一次的状态向量,因此靠补0的方式进行屏蔽是不彻底的。 而CNN是卷积操作,补0的位置对卷积结果没有影响,即补0和mask两种方式的结果是一样的,因此大家为了省事起见,就普遍在CNN使用补0的方法了。
-
-
-
数据偏斜,类别不平衡
https://zhuanlan.zhihu.com/p/32940093
-
如何高效的利用不同的特征和模型
https://blog.csdn.net/zzc15806/article/details/79592577
一个重要的方法就是进行融合(fusion)。典型的fusion方法有early fusion和late fusion。顾名思义,early fusion就是在特征上(feature-level)进行融合,进行不同特征的连接(concatenate),输入到一个模型中进行训练;late fusion指的是在预测分数(score-level)上进行融合,做法就是训练多个模型,每个模型都会有一个预测评分,我们对所有模型的结果进行fusion,得到最后的预测结果。常见的late fusion方法有取分数的平均值(average)、最大值(maximum)、加权平均(weighted average),另外还有采用Logistics Regression的方法进行late fusion。总之,方法很多,可视情况采取。
-
神经网络训练时对输入有什么特别的要求
https://www.zhihu.com/question/47908908
-
输入特征最好不相关。如果某些维输入的相关性太强,那么网络中与这些输入神经元相连的权重实际上起到的作用就是相似的,训练网络时花在调整这些权重之间关系上的力气就白费了。
-
上面说的输入的相关是指所有训练数据某些维度上相关,而不是说某些训练数据在所有维度上相关。在你举的例子中,如果相似数据都非常接近,那么这些数据其实是冗余的,可以去掉一部分;如果相似数据之间的方差足够大,那么这种方差就能增强模型的鲁棒性。
-
如果你不使用minibatch,那么没有影响。
-
需要归一化,否则训练过程中容易遇到数值上的困难。
-
罚金预测类似问题解决案例
-
房价预测问题在 Kaggle 上有一个比赛,有较多可以参考的解答。
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/overview
https://www.kaggle.com/marsggbo/kaggle/output
https://zh.d2l.ai/chapter_deep-learning-basics/kaggle-house-price.html#%E5%8F%82%E4%B8%8E%E8%AE%A8%E8%AE%BA
https://zhuanlan.zhihu.com/p/34904202
https://zhuanlan.zhihu.com/p/39429689
主要流程和方法总结如下:
-
数据预处理
- 深度学习需要将连续数值的特征标准化
- 将离散特征转成指示特征,需要注意顺序标签,顺序变量之间存在固有的顺序,比如 (低, 中, 高)
- 处理缺失数据
- 如果缺失的数据过多,可以考虑删除该列特征。
- 用平均值、中值、分位数、众数、随机值等替代。但是效果一般,因为等于人为增加了噪声。
- 用插值法进行拟合。
- 用其他变量做预测模型来算出缺失变量。效果比方法1略好。有一个根本缺陷,如果其他变量和缺失变量无关,则预测的结果无意义。
- 最精确的做法,把变量映射到高维空间。比如性别,有男、女、缺失三种情况,则映射成3个变量:是否男、是否女、是否缺失。缺点就是计算量会加大。
- 分析标签
- count, mean, std, min, max, 25%, 50%, 75%
- 分布直方图
- 峰度(>0表示比正态分布陡峭)、偏度(>0表示长尾在右)
- 特征选择
- 分析特征字段的含义
- 类别型特征:特征-标签的箱图
- 连续型特征:特征-标签的散点图,删除异常点
- 特征间的关系矩阵和关系点图
- 卡方检验
- 学习器自动选择特征,特征工程在深度学习中不是很重要
- 特征降维:PCA
-
训练模型
- 损失函数
-
MSE:均方误差
-
RMSE:均方根误差
-
log-RMSE:对数均方根误差
-
MAE:平均绝对误差
-
-
Adam 优化算法:相对于小批量随机梯度下降 (SGD),对学习率相对不那么敏感。
- 交叉验证:训练数据集分为 k 个子数据集,使用 k-1 个训练模型,1 个验证模型。其中验证集用于调超参数,多次使用,以不断调参,测试集加试以验证泛化能力性能,仅仅使用一次。
- 损失函数
以下是用深度学习预测房价的一些经验:
-
前提:地產商的資料庫一定要非常大,data 分佈夠多夠廣。
-
数据预处理:将參數(feature) 归一化为[0,1] 或者 [-1, 1],原因是在 gradient descant 前拉闊過窄的參數維度,那麼下降就會加快。
-
模型架构:CNN 最後幾層的 Fully Connected 拿出來就是了,input layer 數目是參數的數目,output layer 是要求回歸的維度數目。前面的输入层以及隐藏层没啥说的,都一样。不同的在于最后输出层(一个节点),一个sum将前一层的所有output加和输出作为预测值。也就是说,最后一层只有一个cell,并且其output只有一维,并且无需激活函数,或者换成线性变换即可。而普通的分类任务,最后一层为softmax分类器,属于非线性映射。
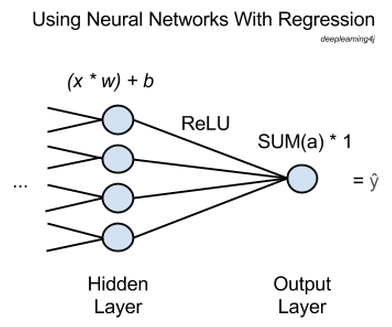
-
神经元数目:越多越好,最好兩層以上,就是訓練會慢一點
-
损失函数:分类任务的 loss fun 一般适合用 cross_entropy , 而回归问题的用 MSE 最好。Mean Absolute Error 太易進入到不好的local minimum中。
-
激活函数:
i) tanh, sigmoid :都是差不多,可以直接拿來用。
ii) relu : 這個會令回歸出來的東西不太smooth。
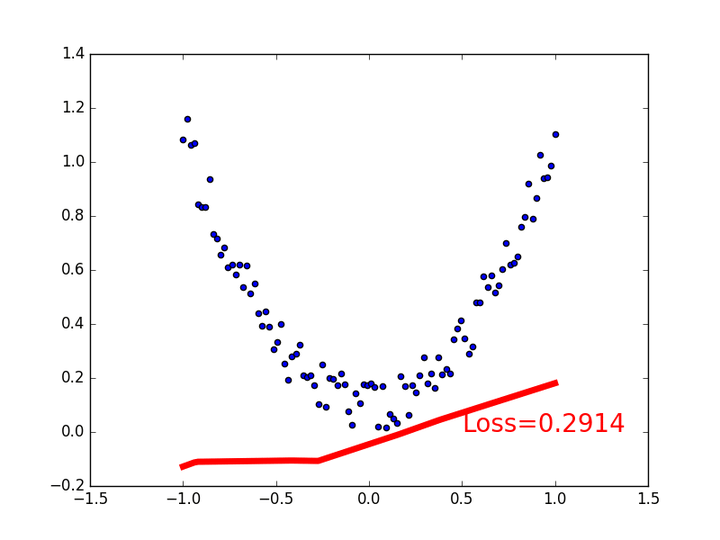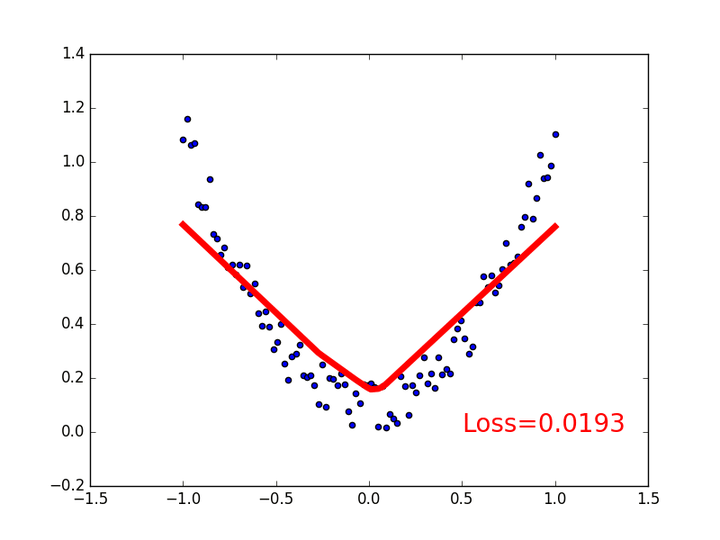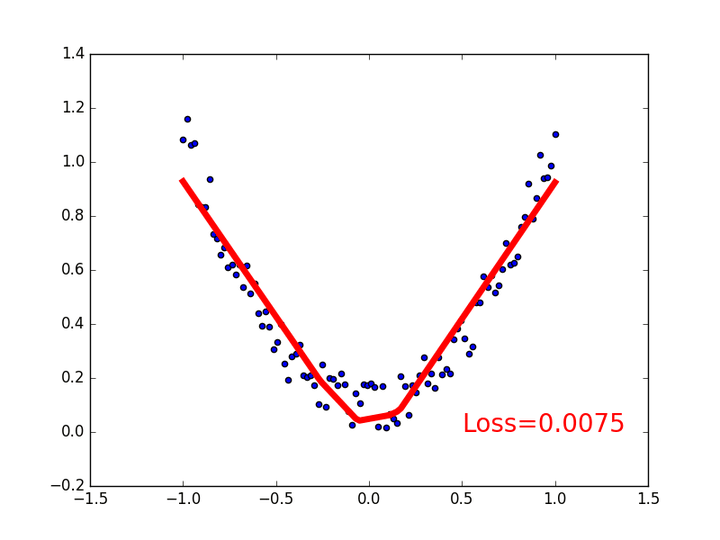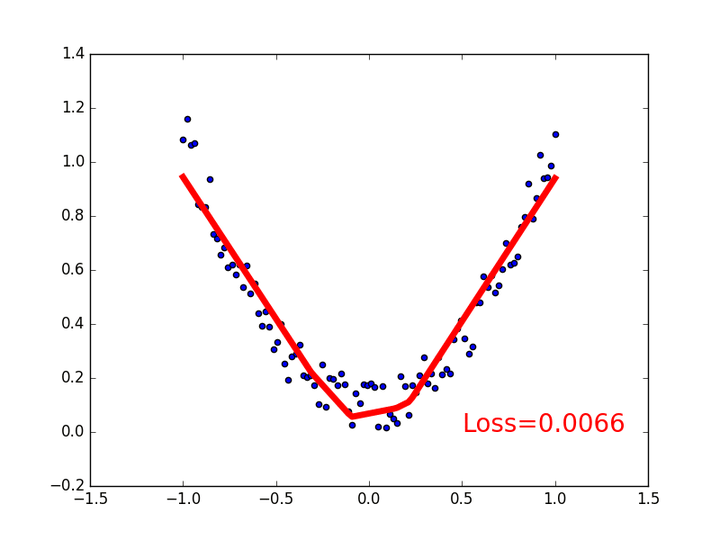
relu 的問題就是圖片中部,回歸的function “起角”不夠smooth,而且非常容易在訓練當中死亡,所以就不要用了。
iii) softplus : 這個不容易過飽和,效果也不錯。
以上各 function 的output layer 都要設置成linear layer (y= mx+C那個),那才能令你的NN function output range 達至 (-infinite,infinite)
-
过拟合
i) dropout: 不單在CNN 在 regression 對 overfitting 也是神器,代價是準確度只能下降到某個數字(如1%)就停了
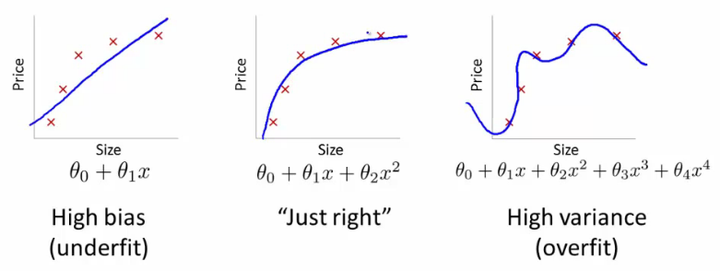
ii) L1 L2 : 可以用,但會令function的non linear特性有所減低,最極端就像下圖中underfit那樣失去曲的特性
-
準確度及難度
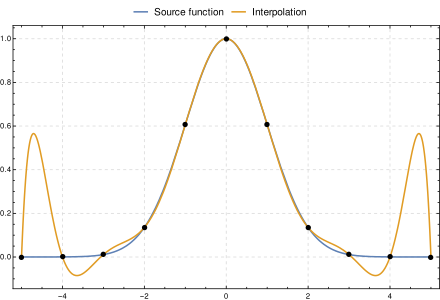
個人經驗,NN fit 出來的function特性跟Lagrangian interpolation有點像,下圖就是Lagrangian interpolation的例子
-
data point 與data point 中間會出現上突/下突的情況 (圖片左右兩邊) ,這個就是為何data point 要多的原因,因為data point 越多越密,突起的情況就會被減輕,同時用dropout也是為了減輕突起的問題
-
不要幻想 extrapolation,你覺得問香港地產經紀北京的樓價靠譜嗎? 後果就是左右兩邊的橙線
除了這一些,準確度還是不錯的,個人做的 NN regression 誤差普遍在0.5%~2%之間,準確度與 data point 密度有關,而同一項目用 gradient boosting (XGB) 做了幾天都做不了這麼準。但說到底都是 deep learning,比起其他回歸的 method 只用幾~幾十分鍾,在 NN底下沒 GPU 跟十多個小時的 training time 是吃不消的。
-
-
相关模型
-
https://blog.csdn.net/ybdesire/article/details/74780130 文章中指出了不同神经网络适用的范围。
- DBN 用于通用的分类问题
- RNN 用于序列化学习,时间序列
- CNN 用于图像、音频、文本分类
- RBM 用于特征提取
- Autoencoder 用于特征提取。
-
主流深度学习模型
https://zhuanlan.zhihu.com/p/29769502
-
有监督的神经网络
-
神经网络(Artificial Neural Networks)和深度神经网络(Deep Neural Networks)
神经网络的基础模型是感知机(Perceptron),因此神经网络也可以叫做多层感知机(Multi-layer Perceptron),简称MLP。
应用场景:全连接的前馈深度神经网络(Fully Connected Feed Forward Neural Networks),也就是DNN适用于大部分分类(Classification)任务,比如数字识别等。但一般的现实场景中我们很少有那么大的数据量来支持DNN,所以纯粹的全连接网络应用性并不是很强。
-
循环神经网络(Recurrent Neural Networks)和递归神经网络(Recursive Neural Networks)
虽然很多时候我们把这两种网络都叫做RNN,但事实上这两种网路的结构事实上是不同的。而我们常常把两个网络放在一起的原因是:它们都可以处理有序列的问题,比如时间序列等。
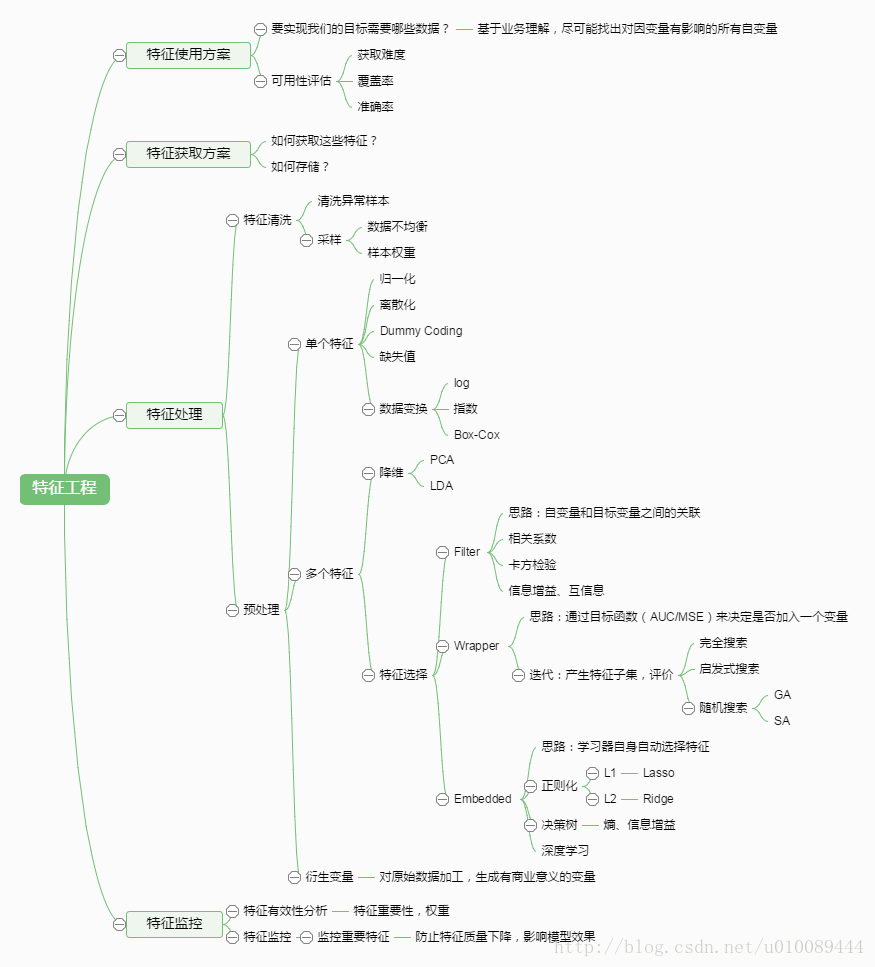
举个最简单的例子,我们预测股票走势用RNN就比普通的DNN效果要好,原因是股票走势和时间相关,今天的价格和昨天、上周、上个月都有关系。而RNN有“记忆”能力,可以“模拟”数据间的依赖关系(Dependency)。为了加强这种“记忆能力”,人们开发各种各样的变形体,如非常著名的Long Short-term Memory(LSTM),用于解决“长期及远距离的依赖关系”。如下图所示,左边的小图是最简单版本的循环网络,而右边是人们为了增强记忆能力而开发的LSTM。
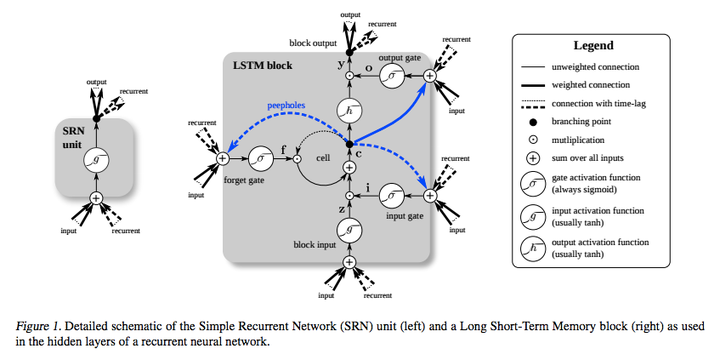
同理,另一个循环网络的变种 - 双向循环网络(Bi-directional RNN)也是现阶段自然语言处理和语音分析中的重要模型。开发双向循环网络的原因是语言/语音的构成取决于上下文,即“现在”依托于“过去”和“未来”。单向的循环网络仅着重于从“过去”推出“现在”,而无法对“未来”的依赖性有效的建模。
递归神经网络和循环神经网络不同,它的计算图结构是树状结构而不是网状结构。递归循环网络的目标和循环网络相似,也是希望解决数据之间的长期依赖问题。而且其比较好的特点是用树状可以降低序列的长度,从
降低到
,熟悉数据结构的朋友都不陌生。但和其他树状数据结构一样,如何构造最佳的树状结构如平衡树/平衡二叉树并不容易。
应用场景:语音分析,文字分析,时间序列分析。主要的重点就是数据之间存在前后依赖关系,有序列关系。一般首选LSTM,如果预测对象同时取决于过去和未来,可以选择双向结构,如双向LSTM。
-
卷积网络(Convolutional Neural Networks)
卷积网络早已大名鼎鼎,从某种意义上也是为深度学习打下良好口碑的功臣。不仅如此,卷积网络也是一个很好的计算机科学借鉴神经科学的例子。卷积网络的精髓其实就是在多个空间位置上共享参数,据说我们的视觉系统也有相类似的模式。
首先简单说什么是卷积。卷积运算是一种数学计算,和矩阵相乘不同,卷积运算可以实现稀疏相乘和参数共享,可以压缩输入端的维度。和普通DNN不同,CNN并不需要为每一个神经元所对应的每一个输入数据提供单独的权重。与池化(pooling)相结合,CNN可以被理解为一种公共特征的提取过程,不仅是CNN大部分神经网络都可以近似的认为大部分神经元都被用于特征提取。
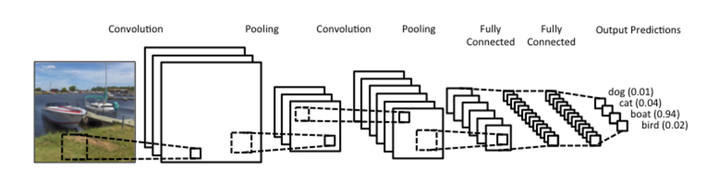
以上图为例,卷积、池化的过程将一张图片的维度进行了压缩。从图示上我们不难看出卷积网络的精髓就是适合处理结构化数据,而该数据在跨区域上依然有关联。
应用场景:虽然我们一般都把CNN和图片联系在一起,但事实上CNN可以处理大部分格状结构化数据(Grid-like Data)。举个例子,图片的像素是二维的格状数据,时间序列在等时间上抽取相当于一维的的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数据。
-
-
无监督的预训练网络
-
深度生成模型(Deep Generative Models)
-
玻尔兹曼机(Boltzmann Machines)和受限玻尔兹曼机(Restricted Boltzmann Machines)
每次一提到玻尔兹曼机和受限玻尔兹曼机我其实都很头疼。简单的说,玻尔兹曼机是一个很漂亮的基于能量的模型,一般用最大似然法进行学习,而且还符合Hebb’s Rule这个生物规律。但更多的是适合理论推演,有相当多的实际操作难度。
而受限玻尔兹曼机更加实际,它限定了其结构必须是二分图(Biparitite Graph)且隐藏层和可观测层之间不可以相连接。此处提及RBM的原因是因为它是深度信念网络的构成要素之一。
应用场景:实际工作中一般不推荐单独使用RBM…
-
深度信念网络(Deep Belief Neural Networks)
主要有两个部分: 1. 堆叠的受限玻尔兹曼机(Stacked RBM) 2. 一层普通的前馈网络。
DBN最主要的特色可以理解为两阶段学习,阶段1用堆叠的RBM通过无监督学习进行预训练(Pre-train),阶段2用普通的前馈网络进行微调。就像我上文提到的,神经网络的精髓就是进行特征提取。和后文将提到的自动编码器相似,我们期待堆叠的RBF有数据重建能力,及输入一些数据经过RBF我们还可以重建这些数据,这代表我们学到了这些数据的重要特征。
将RBF堆叠的原因就是将底层RBF学到的特征逐渐传递的上层的RBF上,逐渐抽取复杂的特征。比如下图从左到右就可以是低层RBF学到的特征到高层RBF学到的复杂特征。在得到这些良好的特征后就可以用第二部分的传统神经网络进行学习。

多说一句,特征抽取并重建的过程不仅可以用堆叠的RBM,也可以用后文介绍的自编码器。
应用场景:现在来说DBN更多是了解深度学习“哲学”和“思维模式”的一个手段,在实际应用中还是推荐CNN/RNN等,类似的深度玻尔兹曼机也有类似的特性但工业界使用较少。
-
生成式对抗网络(Generative Adversarial Networks)
生成式对抗网络用无监督学习同时训练两个模型,内核哲学取自于博弈论…
简单的说,GAN训练两个网络:1. 生成网络用于生成图片使其与训练数据相似 2. 判别式网络用于判断生成网络中得到的图片是否是真的是训练数据还是伪装的数据。生成网络一般有逆卷积层(deconvolutional layer)而判别网络一般就是上文介绍的CNN。下图左边是生成网络,右边是判别网络。
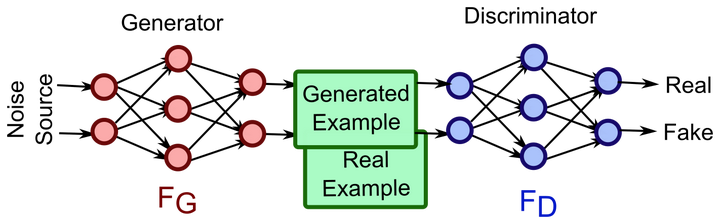
熟悉博弈论的朋友都知道零和游戏(zero-sum game)会很难得到优化方程,或很难优化,GAN也不可避免这个问题。但有趣的是,GAN的实际表现比我们预期的要好,而且所需的参数也远远按照正常方法训练神经网络,可以更加有效率的学到数据的分布。
另一个常常被放在GAN一起讨论的模型叫做变分自编码器(Variational Auto-encoder),有兴趣的读者可以自己搜索。
应用场景:现阶段的GAN还主要是在图像领域比较流行,但很多人都认为它有很大的潜力大规模推广到声音、视频领域。
-
-
自编码器(Auto-encoder)
自编码器是一种从名字上完全看不出和神经网络有什么关系的无监督神经网络,而且从名字上看也很难猜测其作用。让我们看一幅图了解它的工作原理…
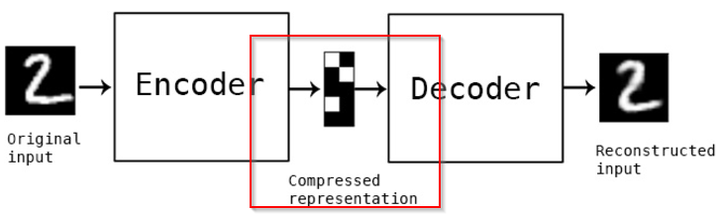
如上图所示,Autoencoder主要有2个部分:1. 编码器(Encoder) 2. 解码器(Decoder)。我们将输入(图片2)从左端输入后,经过了编码器和解码器,我们得到了输出….一个2。但事实上我们真正学习到是中间的用红色标注的部分,即数在低维度的压缩表示。评估自编码器的方法是重建误差,即输出的那个数字2和原始输入的数字2之间的差别,当然越小越好。
和主成分分析(PCA)类似,自编码器也可以用来进行数据压缩(Data Compression),从原始数据中提取最重要的特征。认真的读者应该已经发现输入的那个数字2和输出的数字2略有不同,这是因为数据压缩中的损失,非常正常。
应用场景:主要用于降维(Dimension Reduction),这点和PCA比较类似。同时也有专门用于去除噪音还原原始数据的去噪编码器(Denoising Auto-encoder)。
-
-
-
RNTN: 递归神经张量网络
https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf
https://skymind.ai/wiki/recursive-neural-tensor-network
递归神经张量网络(RNTN)是用于自然语言处理的神经网络。它们具有树结构,每个节点都有一个神经网络。可以使用递归神经张量网络进行边界分割,以确定哪些词组是正情感,哪些是负情感,这同样适用于整个句子。单词向量用作特征,并作为顺序分类的基础。然后将它们分组为子短语,并将子短语组合成一个可以按情感和其他指标分类的句子。
Word2Vec:构建工作RNTN的第一步是词向量化,可以使用Word2vec算法来完成。Word2Vec将单词语料库转换为向量,然后可以将其投入向量空间以测量它们之间的余弦距离,即他们之间的相似性。递归神经张量网络需要像 Word2vec 这样的外部组件。为了用神经网络分析文本,可以将单词表示为参数的连续向量。这些单词向量不仅包含有关单词的信息,还包含有关周围单词的信息; 即单词的上下文,用法和其他语义信息。
为了组织句子,递归神经张量网络使用区域分析,它将单词分组成句子中较大的子短语; 例如,名词短语(NP)和动词短语(VP)。该过程依赖于机器学习,并允许对这些单词和短语进行额外的语言观察。通过解析句子,将它们构造为树。树后来被二值化,这使数学更方便。对树进行二值化意味着确保每个父节点都有两个子叶。句子树的根在顶部,叶子在底部,一个自上而下的结构,如下所示:

整个句子位于树的根部(顶部); 每个单词都是一个叶子(在底部)。
最后,可以从Word2vec中获取单词向量,并替换树中的单词。
-
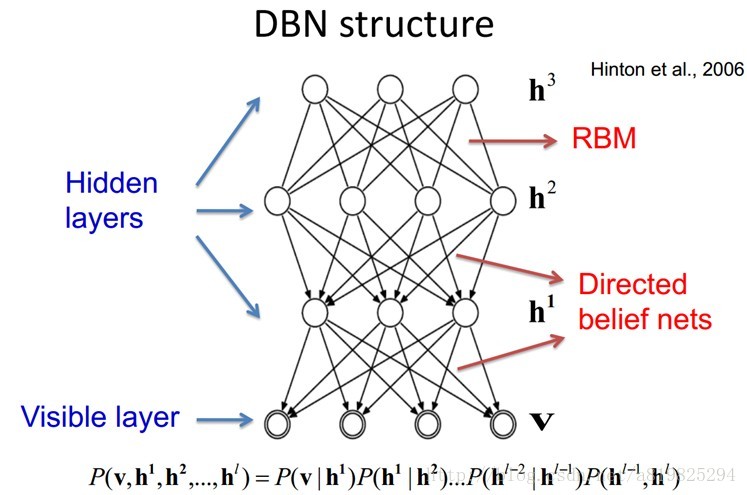
DBN: 深度信念网络
https://blog.csdn.net/a819825294/article/details/53608141
-
概述
深度信念网络是一个概率生成模型,与传统的判别模型的神经网络相对,生成模型是建立一个观察数据和标签之间的联合分布,对P(Observation Label)和 P(Label Observation)都做了评估,而判别模型仅仅而已评估了后者,也就是P(Label Observation)。 DBNs由多个限制玻尔兹曼机(Restricted Boltzmann Machines)层组成,一个典型的网络结构如图所示。这些网络被“限制”为一个可视层和一个隐层,层间存在连接,但层内的单元间不存在连接。隐层单元被训练去捕捉在可视层表现出来的高阶数据的相关性。
-
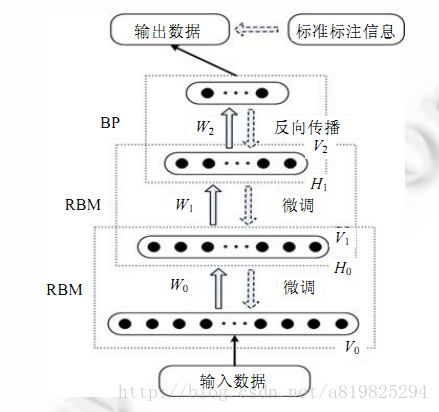
经典结构
经典的DBN网络结构是由若干层 RBM 和一层 BP 组成的一种深层神经网络, 结构如图所示.
DBN 在训练模型的过程中主要分为两步:
第 1 步:分别单独无监督地训练每一层 RBM 网络,确保特征向量映射到不同特征空间时,都尽可能多地保留特征信息;
第 2 步:在 DBN 的最后一层设置 BP 网络,接收 RBM 的输出特征向量作为它的输入特征向量,有监督地训练实体关系分类器.而且每一层 RBM 网络只能确保自身层内的权值对该层特征向量映射达到最优,并不是对整个 DBN 的特征向量映射达到最优,所以反向传播网络还将错误信息自顶向下传播至每一层 RBM,微调整个 DBN 网络.RBM 网络训练模型的过程可以看作对一个深层 BP 网络权值参数的初始化,使DBN 克服了 BP 网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点.
上述训练模型中第一步在深度学习的术语叫做预训练,第二步叫做微调。最上面有监督学习的那一层,根据具体的应用领域可以换成任何分类器模型,而不必是BP网络。
-
扩展
DBN的灵活性使得它的拓展比较容易。一个拓展就是卷积DBNs(Convolutional Deep Belief Networks(CDBN))。DBN并没有考虑到图像的2维结构信息,因为输入是简单的从一个图像矩阵一维向量化的。而CDBN就是考虑到了这个问题,它利用邻域像素的空域关系,通过一个称为卷积RBM的模型区达到生成模型的变换不变性,而且可以容易得变换到高维图像。DBN并没有明确地处理对观察变量的时间联系的学习上,虽然目前已经有这方面的研究,例如堆叠时间RBMs,以此为推广,有序列学习的dubbed temporal convolutionmachines,这种序列学习的应用,给语音信号处理问题带来了一个让人激动的未来研究方向。
目前,和DBN有关的研究包括堆叠自动编码器,它是通过用堆叠自动编码器来替换传统DBN里面的RBM。这就使得可以通过同样的规则来训练产生深度多层神经网络架构,但它缺少层的参数化的严格要求。与DBN不同,自动编码器使用判别模型,这样这个结构就很难采样输入采样空间,这就使得网络更难捕捉它的内部表达。但是,降噪自动编码器却能很好的避免这个问题,并且比传统的DBN更优。它通过在训练过程添加随机的污染并堆叠产生场泛化性能。训练单一的降噪自动编码器的过程和RBM训练生成模型的过程一样。
-
-
AutoEncoder: 自编码
http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/2-5-autoencoder/
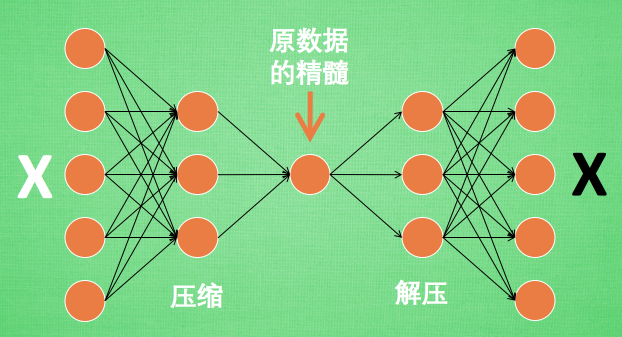
有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了. 所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分.
前半部分叫做编码器 Encoder,编码器类似 PCA 主成分分析的功能,对输入数据进行降维,提取主要特征。
后半部分叫做解码器 Decoder,解码器将精髓信息解压成原始信息,可以认为是类似 GAN 的生成器。
-
深度学习在推荐系统上的应用
https://zhuanlan.zhihu.com/p/33214451
- 优点
- 能够直接从内容中提取特征,表征能力强
- 容易对噪声数据进行处理,抗噪能量强
- 可以使用RNN循环神经网络对动态或者序列数据进行建模
- 可以更加准确的学习user和item的特征
- 深度学习便于对负责数据进行统一处理
-
Learning item embeddings & 2Vec models
-
Embedding as MF
Embedding 就是从输入数据中学习到另外一组向量值的过程,通过另外一组向量去表达原来实际的向量。
在推荐系统里面我们经常会使用基于矩阵分解的协同过滤的方法,去得到Latent feature vector,也就是潜在特征向量。而矩阵分解实际上就是学习user & item的embedding向量。

MF可以看做一个简单的神经网络
输入是一个one-hot编码的用户id,对于数据的隐层权重向量来说是代表用户特征矩阵。对于隐层则可以是代表用户特征向量 user feature vector,对于隐层的输出权重向量来说代表item特征矩阵, Item feature maxtrix。最后该神经网络的输出则是用户对于该item的偏好。

-
Word2Vec
word2vec 对于做自然语言处理的人们来说,自然熟悉不过了。word2vec顾名思义就是把单词编码成向量,例如单词 “拉稀” 编码成 [0.4442, 0.11345]。
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
Word2Vec模型中,主要有Skip-Gram和Continous Bag of Words (CBOW)两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
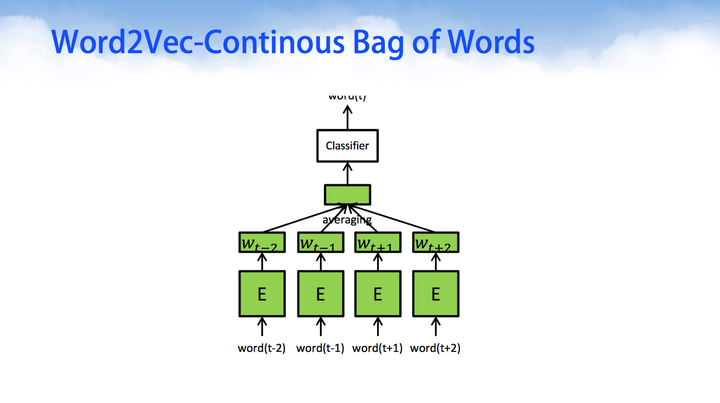
Word2Vec-Continous Bag of Words (CBOW)
Continous Bag of Words 连续词包的目标是使得给定上下文的目标词概率最大化。对于这样的深度学习模型来说,输入是经过one-hot编码的向量;经过神经网络的第一层E处,是对单词one-hot向量的embedding操作;对于中间隐层,是上下文的压缩编码特征;经过softmax转变后得到给定语料单词的最大似然估计。

上面就是word2vec的一个简单过程,经过上面过程我们可以对单词进行编码,然后对所有单词进行汇总求和分类,得到最后的语料向量。
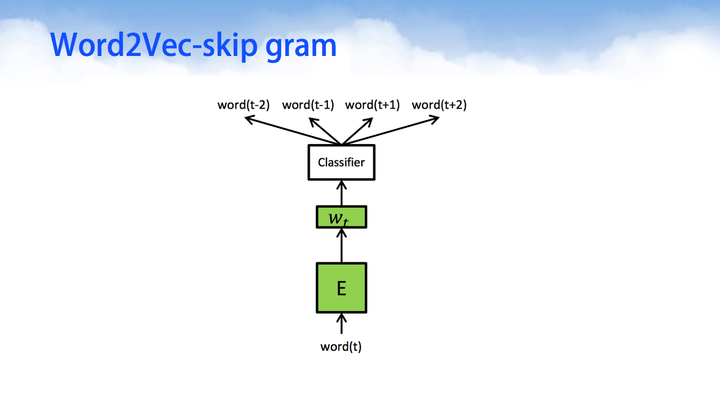
Word2Vec-skip gram
skip-gram与CBOW相比,只有细微的不同。skip-gram的输入是当前词的词向量,而输出是周围词的词向量。也就是说,通过当前词来预测周围的词。
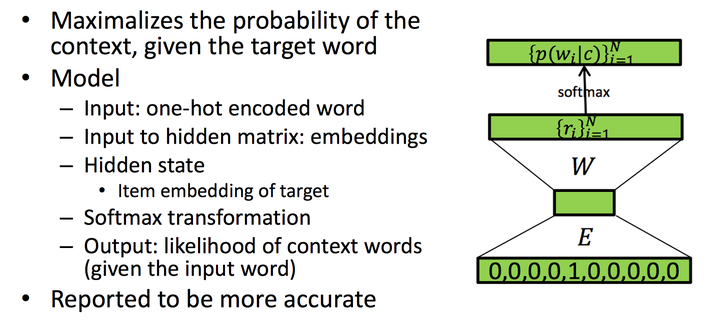
其中word2Vec部分与CBOW相同,但是根据论文和实践证明,skip-gram的方式得到的准确率会更高。表征能力也更强。
-
xxx2vec
当然,最常用的是上面2中,但是不乏近年来又衍生了更多的2vec变种,例如有的利用段落信息,有的利用整个文本的信息,有的则是在更高维度的item上进行2vec操作。下面我们一起来看看更多的衍生算法,至于说哪个算法哪个实现方式更好?笔者觉得应该尊重原数据,建立在理解业务的基础上进行操作,例如对于短视频的推荐与对于电影的推荐是不同,短视频有其特别的属性,例如搞笑、时间短、标题党等诸多属性需要去做去噪等工作。
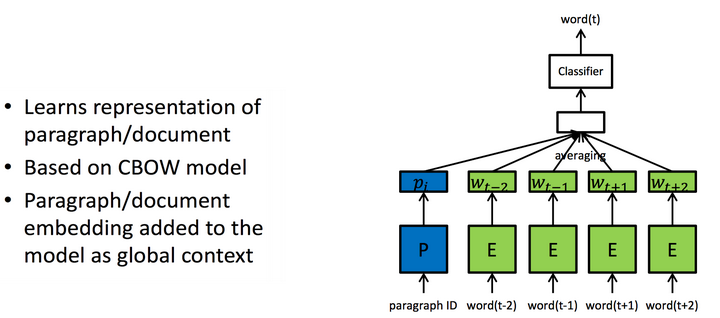
其中有Paragraph2vec基于CBOW,把段落的ID作为属性也纳入计算当中。
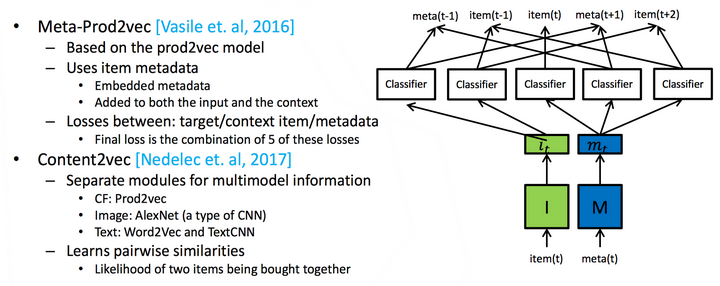
不过我们也可以像Content2Vec或者meta-prod2vec那样组合更多的特征进行处理,在这里以后再也不要说深度学习不需要特征工程时间了,深度学习的表征能力很好,但是工程师们仍然需要耗费大量的时间在选择特征这一件事情上,不懂特征工程的机器学习工程师不是好的机器学习工程师。
-
-
Deep Collaborative filtering 深度协同过滤
-
Auto-encoders
Model-based方法的目的就是学习到User的隐向量矩阵U与Item的隐向量矩阵V。我们可以通过深度学习来学习这些抽象表示的隐向量。
Autoencoder(AE)是一个无监督学习模型,它利用反向传播算法,让模型的输出等于输入。Autoencoder利用AE来预测用户对物品missing的评分值,该模型的输入为评分矩阵R中的一行(User-based)或者一列(Item-based),其目标函数通过计算输入与输出的损失来优化模型,而R中missing的评分值通过模型的输出来预测,进而为用户做推荐。
原论文的思路如下所示,对于autoencoders是一个自动编解码器,对于同源编解码器的训练学习过程中,我们的输入等于输出,中间编码向量作为特征向量。

该神经网络设计的编解码器一般只有3层,编码层(输入层),隐层,解码层(输出层)。
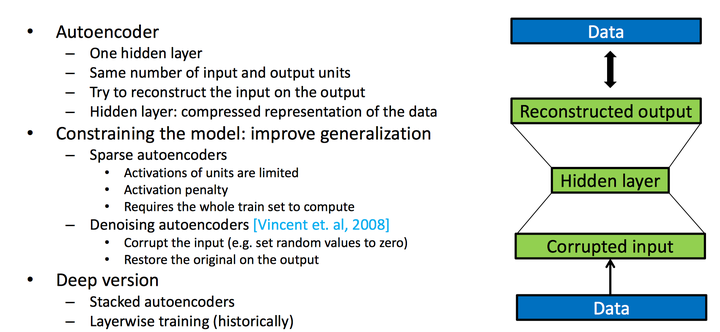
stacked denoising autoencoders
自从Autoencoders出现之后,确实是个好思想,但是后面我们迎来了DCL的黄金时代,确实DCL这篇文章首次提出让深度学习与协同过滤相结合,效果在开源数据集中取得了一点点上升,即使是一点点上升,但也是很重要的,因为把深度学习与协同过滤有机地集合了在一起。
Denoising Autoencoder(DAE)是在AE的基础之上,对输入的训练数据加入噪声。所以DAE必须学习去除这些噪声而获得真正的没有被噪声污染过的输入数据。因此,这就迫使编码器去学习输入数据的更加鲁棒的表达,通常DAE的泛化能力比一般的AE强。Stacked Denoising Autoencoder(SDAE)是一个多层的AE组成的神经网络,其前一层自编码器的输出作为其后一层自编码器的输入。

在SDAE的基础之上,又提出了Bayesian SDAE模型,并利用该模型来学习Item的隐向量,其输入为Item的Side information。该模型假设SDAE中的参数满足高斯分布,同时假设User的隐向量也满足高斯分布,进而利用概率矩阵分解来拟合原始评分矩阵。该模型通过最大后验估计(MAP)得到其要优化的目标函数,进而利用梯度下降学习模型参数,从而得到User与Item对应的隐向量矩阵。
Collaborative Recurrent Autoencoder
后来同一个作者又捣鼓出了CRAE.使用循环神经网络代替浅层的神经网络。看截图的风格,可以很清晰地看到肯定是出于同一个作者之手。

-
DeepCF
下面我们要介绍几个16-17年发表的DeepCF网络模型,虽然下面的网络模型不一定有用,但是其思想值得借鉴。
MV-DNN是基于多主题推荐,一个用户与多个主题内容进行建模组成一个深度神经网络。有n个用户则有n个神经网络,大量的神经网络进行组合成为一个庞大的DNN模型群。
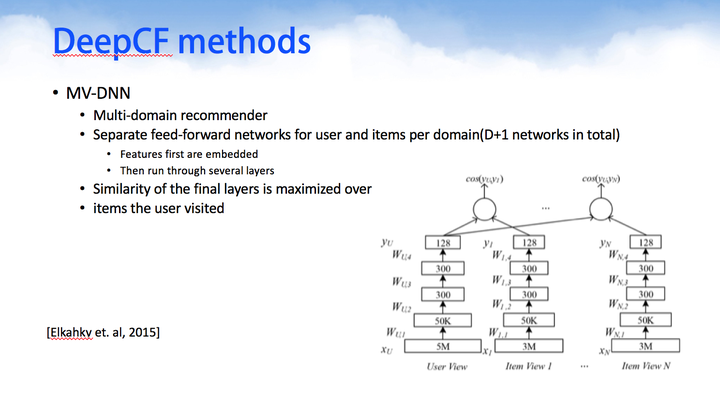
TDSSM与MV-DNN有点类似,用于对用户和item的短暂/临时数据进行一起建模。

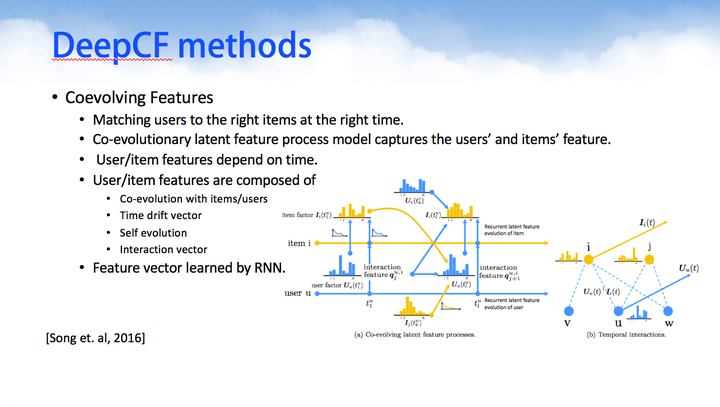
Coevolving Features匹配上用户与item的瞬时信息,因为其相信随着用户在系统的浏览或者购买过程中,用户的选择偏好会不断改变,而所被选择的物品也会不断变化,这两者是一起发生变化的co-evolutionary。
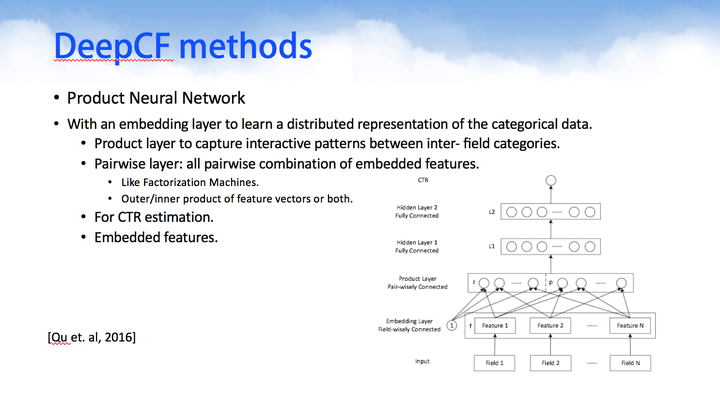
Product Neural Network则是把产品的目录结构也纳入神经网络中进行计算,计算的同时考虑了产品目录结构属性。
-
google recommendations
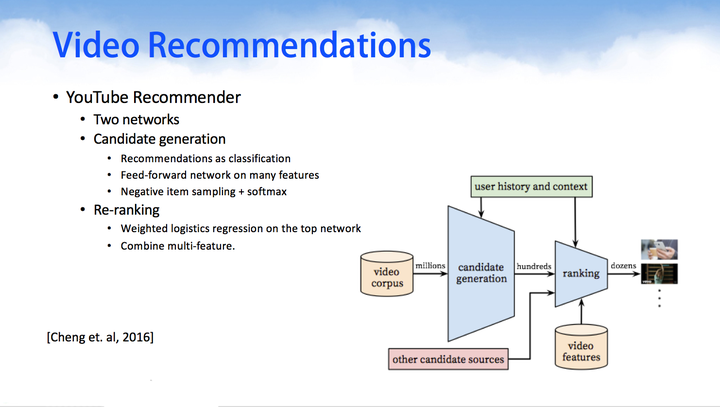
下面两个是google近年来推出较为经典的使用深度学习做推荐算法的框架。其中Wide & Deep Learning网络模型由Wide Models和Deep Models组合而成,这里的特征组合方式非常巧妙。

YouTube Recommender,在今年的推荐系统顶级会议RecSys上,Google利用DNN来做YouTube的视频推荐。通过对用户观看的视频,搜索的关键字做embedding,然后在串联上用户的side information等信息,作为DNN的输入,利用一个多层的DNN学习出用户的隐向量,然后在其上面加上一层softmax学习出Item的隐向量,进而即可为用户做Top-N的推荐。
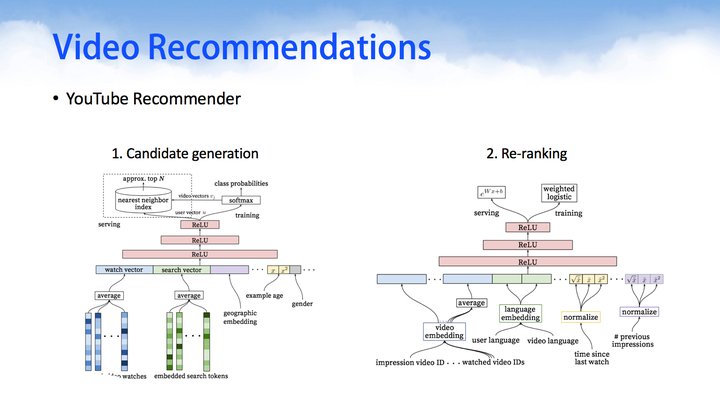
-
-
Feature extraction directly from content 从内容中提取特征
在基于内容/上下文特征的推荐中,我们的注意力对内容/上下文content中,例如有图像、文本、语音,这些内容都可以通过深度学习建模,获得其高维特征或者分类属性,然后基于协同过滤算法CF和基于内容的过滤算法CBF的混合组合,进行推荐。

针对于图像识别一类任务,深度学习已经取得了举足的进展。深度神经挽留过模型设计一开始的时候模型权重越多模型越大,其精度越高,后来先后出现了GoogleNet、InceptionV1、INceptionV2、InceptionV3,resNet等著名的开源深度网络架构之后,在取得相同或者更高精度之下,其权重参数不断下降。值得注意的是,并不是意味着横坐标越往右,它的运算时间越大。在这里并没有对时间进行统计,而是对模型参数和网络的精度进行了纵横对比。其中有几个网络非常值得学习和经典的有:AlexNet、LeNet、GoogLeNet、VGG-16\VGG-19。
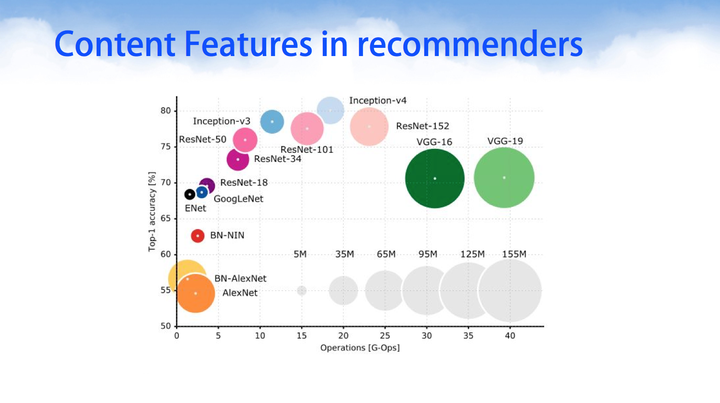
针对文本处理我们在此前已经介绍过一系列的Word2vec技术,而音频音乐方面的内容可以使用循环神经网络RNN进行序列数据建模。
-
Session-based recommendation with RNN 使用RNN从会话中推荐

首先介绍下 session-based 的概念:session 是服务器端用来记录识别用户的一种机制。典型的场景比如购物车,服务端为特定的对象创建了特定的 Session,用于标识这个对象,并且跟踪用户的浏览点击行为。我们这里可以将其理解为具有时序关系的一些记录序列。
传统的两类推荐方法——基于内容的推荐算法和协同过滤推荐算法(model-based,memory-based)在刻画序列数据中存在缺陷:每个 item 相互独立,不能建模 session 中 item 的连续偏好信息。

在模型构建的时候,上图使用了GRU,但是我们可以有很多选择例如LSTM等,当然这些模型神经元的选择主要原因是为了防止梯度消散对长时间序列记忆力下降而出现的。
我们出现了基于时间序列数据建模的循环神经网络RNN,把用户的session信息看作是历史序列数据,用户的行为CTR作为循环神经网络RNN的预测输出。

- hybird combination algorithm 混合基于深度学习的推荐系统
- 优点
-
Neural Collaborating Filtering 神经协同过滤
https://github.com/hexiangnan/neural_collaborative_filtering
-
整体框架
输入层:包括用户和物品的特征,可以通过上下文感知、基于内容的方法得到。文章中为用户 id 和物品 id。
嵌入层:将稀疏的表示投射到高维的稠密的向量,得到用户和物品的隐向量。
神经协同过滤层:多层感知机。

-
GMF Generalized Matrix Factorization 广义矩阵分解
由于输入层 one-hot 编码的用户、物品 id,得到的嵌入层向量可以视为隐向量。将用户隐向量与物品隐向量点乘,经过输出层的边缘权重和激活函数(式9)。
-
MLP 多层感知机
将用户向量与物品向量直接拼接 (concatenate) 起来。向量连接不能解释用户和物品的隐特征的交互关系,因此利用多层感知机中的隐藏层来学习用户和物品的隐特征的交互关系。
-
GMF 和 MLP 的融合
一个直观的策略是让 GMF 和 MLP 共享相同的嵌入层,然后结合它们的输出。然而 GMF 和 MLP 共享的嵌入层可能会限制融合模型的性能。为了给模型提供灵活性,文献允许 GMF 和 MLP 学习不同的嵌入层,并将它们的最后一层隐藏层拼接起来。
预训练:由于目标函数的非凸特性,基于梯度的优化只能得到局部最优解。参数初始化在模型的收敛和性能上起到很重要的作用。文献利用 Adam 预训练参数,再用传统的 SGD 进一步优化。

-
-
深度学习中的注意力机制
https://blog.csdn.net/qq_40027052/article/details/78421155
-
人类的视觉注意力
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
-
Encoder-Decoder框架
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对< Source,Target >,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。
如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
-
Attention 模型
-
-
采用文档上下文和物品统计的混合推荐系统
https://github.com/cartopy/ConvMF
-
总体框架

- 嵌入层: 将文档转换为尺寸为 (每个词的嵌入维度) * (文档中的词数) 的矩阵。
- 卷积层
- 池化层
- 输出层
-
加入文档上下文信息
公式 5 中,物品的隐向量中的每一列赋值为 CNN 的输出和一个高斯噪声。
-
通过物品统计 (即物品的评分数) 基于描述文档建模物品的隐因子时,考虑高斯噪声的不同
有很多评分的物品应该被显示建模为有更小方差的高斯噪声,而有很少评分的物品应该被显示建模为有更大方差的高斯噪声。
-
-
用于回归和时间序列预测的集成深度学习
https://ieeexplore.ieee.org/document/7015739
- 提出深度学习信念网络的集成来回归和时间序列预测。
- 利用支持向量回归模型 (SVR) 来总计多个 DBN 的输出。
-
注意力组推荐
https://github.com/LianHaiMiao/Attentive-Group-Recommendation
-
动机
常见的组推荐策略有平均策略、最小痛苦策略、最大满足策略、专家策略。我们认为这些预定义的策略是数据相关的,缺少动态调整组成员权重的灵活性。当一个组制定不同类型的物品的决定时,这个灵活性是特别有用的。
-
方法
文中图 2
$g_{l}(j)=$ user embedding aggregation + group preference embedding
用户嵌入总计:执行一个组$g_{l}$成员嵌入的权重加和。
组偏好嵌入:意图是考虑一个组的整体偏好。
-
与 NCF 一起交互学习
文中图 1、图 3
-
-
基于物品的协同过滤算法
https://blog.csdn.net/hx2017/article/details/77924244
UserCF和ItemCF的综合比较:
-
UserCF(适用新闻推荐等) 给用户推荐那些和他相同兴趣爱好的用户喜欢的物品,反映用户所在的小型兴趣群体中物品的热门程度。
-
ItemCF(适用图书、电商、电影网站等)
给用户推荐那些和他之前喜欢的物品类似的物品,更加个性化,反映了用户自己的兴趣传承。
-
-
行政处罚智能裁量研究
- 将模糊推理和径向基函数神经网络 (RBF) 结合,建立模糊神经网络,获取案例中的专家知识。
- 利用数据仓库技术管理案例,利用 KNN 进行相似案例检索,从而对神经网络进行解释。
-
基于排序学习的推荐算法研究综述
-
摘要
- 如果仅仅依据用户对物品的评分产生推荐推荐结果并不能准确地体现用户的偏好
- 物品间的排序比传统推荐算法依据物品评分大小的顺序进行推荐更为重要
- 传统推荐算法如基于内容的推荐算法、协同过滤推荐算法等不需要训练阶段,直接通过计算用户之间的相似度;二基于排序学习的推荐算法是一种监督性学习
-
传统推荐算法
- 基于内容的推荐算法
- 协同过滤推荐算法:基于用户、基于物品
- 混合推荐算法
-
点级排序学习
- 隐语义模型 latent factor model
- 得分:式1、式3
- 损失函数:式2,平方误差
- OrdRec:用户对物品不同操作的等级
- IFRM:在用户对大多数物品的评分都很高或者都很低的情况下,式1预测用户对物品的评分高低并不意味着用户是否会选择该用户。
-
对级排序学习
-
点级排序学习完全从单个物品的分类得分角度计算,没有考虑物品之间的顺序关系。
-
对级排序学习的主要思想是将排序问题形式化为二元分类问题,偏重于对物品顺序关系是否合理进行判断。
-
Pessiot 等人:采用矩阵分解的隐语义模型,将损失函数定义为基于评分预测所得到的物品对偏序关系中,被预测错误的物品对数量。
-
LRHR:采用对级排序学习方法 RankSVM 进行排序。RankSVM 是一个经典的排序学习方法,它将 物品对的偏序关系作为特征向量进行训练,并将排序问题转化为分类问题。
-
Liu 等人:根据用户对物品的排序获取目标用户的相似用户, 然后根据相似用户的偏好对目标用户生成推荐列表. 采用了Kendall 排序相关系数衡量两个用户评分物品交集的排序相似度,得到与目标用户具有相似偏好的用户集合N(u), 训练两个物品之间的排序函数见公式(10).
-
Rendle 等人:如果用户 u 浏览过物品 i, 则比起其他没有被浏览过的物品而言, 用户 u 更喜欢该物品.
-
Pan 等人:用户更倾向于物品集合而非单个物品。
-
存在的问题:对级排序学习只考虑两个物品间的偏序关系,却没有考虑物品出现在推荐列表中的位置. 然而,排在推荐列表前面位置的物品显然更为重要.
解决方法:引入代价敏感函数
-
存在的问题:不同用户评分物品数量差异很大,有些用户有过评分行为的物品对多达上百对,而有些用户却只对十几对物品评过分。
解决方法:对于分布不均匀的数据,可以采用列表级排序学习算法.
-
-
列表级排序学习
- 列表级排序学习技术相比于点级和对级排序学习技术而言,不再将排序问题直接形式化为一个分类或者回归问题,而是直接对物品的排序列表进行优化.
- 目前主要有两种优化方式:直接针对排序的评价指标进行优化、构造损失函数进行优化。
-
信息检索的特征可以分为3大类:
1) Doc本身的特征:Pagerank、内容丰富度、是否是spam、质量值、CTR等
2) Query-Doc的特征:Query-Doc的相关性、Query在文档中出现的次数,査询词的Proximity值(即在文档中多大的窗口内可以出现所有査询词)等。当然,有些Query-Doc的特征不是显式的,而是有Semantic的,即虽然Query在文档中没有出现,但是语义上是有关系的。
3) Query的特征:Query 在所有Query 中的出现次数、比率等
-
RankLib
排序学习库 RankLib 的训练集和测试集的格式为
label qid:$id $featureid:$featurevalue $featureid:$featurevalue ... # description其中,label 为标签,表示文档与检索的相关程度。qid 为检索编号,实际为案例号。feature 为特征,包括文档本身的特征、检索与文档的特征、检索的特征。可以将当前的规范用语与已经输入的规范用语的相似度、规范用语在当前月和当前地区出现的次数和频率、规范用语在近期出现的次数和频率、规范用语在所有时间内出现的次数等等作为特征。
-
-
关键词提取算法原理
https://www.zhihu.com/question/21104071
https://www.jiqizhixin.com/articles/2018-11-14-17
(1) TF-IDF 原理:某一特定文档内的高词语频率,以及该词语在整个文档集合中的低文档频率,可以产生出高权重的 TF-IDF.
词频 TF = 词语在文章中出现次数 / 文章总词数
逆向文档频率 IDF = log (语料库文档总数 / (包含该词的文档数+1))
TF-IDF = TF * IDF
(2) TextRank 原理:TextRank 算法基于 PageRank 算法。
PageRank 用来计算网页的重要性。在每次迭代中,给定页面的PR值(PageRank值)将均分到该页面所链接的页面上。
TextRank 将每个单词作为 PageRank 中的一个节点。设定一个相邻窗口,在同一个窗口中的任两个单词对应的节点之间存在一个无向无权的边。由此计算出每个单词的重要性。
(3) 主题模型:文章由主题构成,主题由单词构成,从而从文本中发现隐含的语义维度。
(4) 一些组合算法在工程上被大量应用以弥补单算法的不足,例如将TF-IDF算法与TextRank算法相结合,或者综合TF-IDF与词性得到关键词等。
(5) 自然语言处理库
HanLP 支持中文分词、词性标注、关键词提取、命名实体识别等功能,并且支持在 Java 和 Python 语言中调用。
-
命名实体识别算法原理
https://easyai.tech/ai-definition/ner/
(1) 利用命名实体识别,识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。
(2) 有监督的学习方法需要利用大规模的已标注语料对模型进行参数训练。目前常用的模型或方法包括隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。值得一提的是,基于条件随机场的方法是命名实体识别中最成功的方法。
(3) 由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是LSTM+CRF、BiLSTM+CRF。
(4) 隐式马尔科夫 (HMM) 模型:P(Y) = \sum_{X} P(Y X)P(X),其中 Y 为观察到的结果, X 为隐藏条件。例如在词性标记中,Y 为单词,X 为单词的词性。 Viterbi 算法:已知观测序列和 HMM 模型的情况下求状态序列。利用动态规划求概率最大的最优路径,回溯逆推状态序列。
(5) 条件随机场 (CRF) 算法:随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有X和Y两种变量,X一般是给定的,而Y一般是在给定X的条件下的输出。CRF 准确的数学语言描述:设X与Y是随机变量,P(Y X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔科夫随机场,则称条件概率分布P(Y X)是条件随机场。

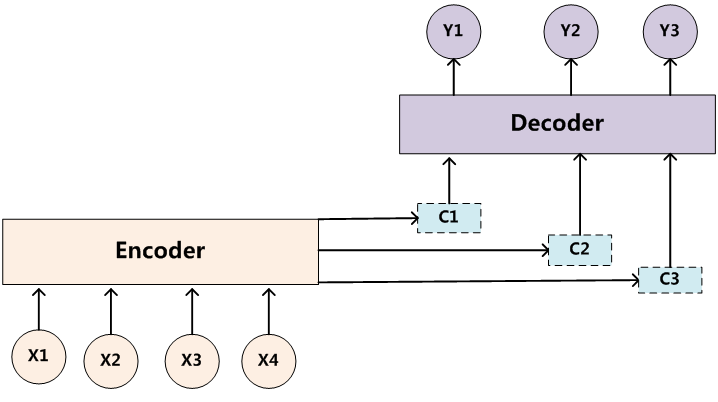
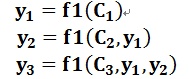

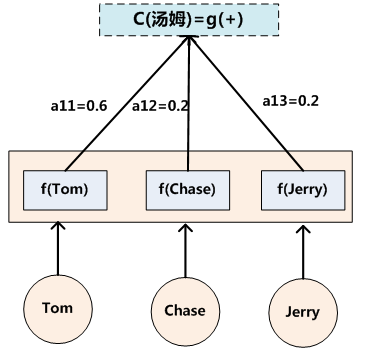
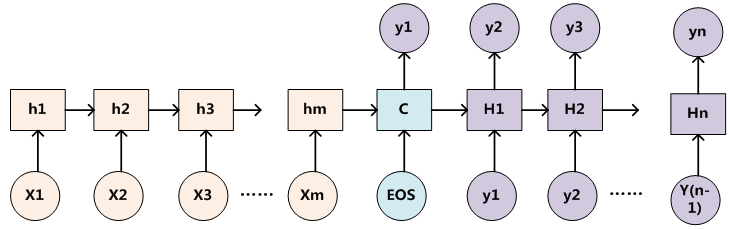

TensorFlow 深度学习框架
-
TensorFlow 基本概念
-
计算图:TensorFlow 中的每一个计算都是计算图上的一个节点,节点之间的边描述计算之间的依赖关系。
TensorFlow 中,系统会自动维护一个默认的计算图,通过 tf.get_default_graph() 函数获取,通过 a.graph 查看张量所属的计算图,通过 tf.Graph 函数生成新的计算图。
-
张量:多维数组。零阶张量是一个数,一阶张量为向量,n 阶张量是 n 阶数组。
TensorFlow 中,一个张量保存了三个属性:名字、维度、类型。
-
会话:TensorFlow 中的会话用来执行定义好的运算。
会话调用方法:
with tf.Session() as sess:
sess.run(result)
其中,sess = tf.Session() 用来创建一个会话,sess.run(result) 用来计算结果,result.eval(session=sess) 具有相同的功能。
TensorFlow 不会生成默认的会话,利用 sess.as_default() 设置默认会话。
-
-
线性回归
输入数据:随机生成的假数据,50 个点的坐标。
输出数据:50 个点的拟合直线的权重和偏差值。
总体功能:利用 TensorFlow 低阶 API,对 50 个点进行线性拟合,拟合出一条直线。
解决的问题:在 TensorFlow 中,利用线性回归的方法对输入进行拟合。
算法流程:
- with tf.Session() as sess 建立了一个 TensorFlow 的会话。
- sess.run(tf.global_variables_initializer()) 对所有的变量进行初始化。
- inputs() 函数定义了张量 X 和 Y。
- inference() 函数用来预测在某个 X 的 Y 值的计算。函数的输入是 X,输出是根据现在的参数预测 Y 的值。
- loss() 函数定义了损失的计算,损失函数为 Y 的真实值与预测值的平方误差。函数的输入是 X、Y,输出的平方误差。
- train() 函数使用梯度下降来训练模型。函数的输入是损失函数,输出的是梯度下降模型。
- 在每次迭代中,sess.run() 函数的输入是计算图和点坐标,输出误差值。
-
逻辑回归
输入数据:MNIST 手写数字图片。
输出数据:手写数字图片识别的准确率。
总体功能:利用 TensorFlow 低阶 API,对手写数字图片进行二分类。
解决的问题:在 TensorFlow 中,利用逻辑回归的方法对输入进行二分类。
算法流程:
- 下载 MNIST 手写数字识别图片的数据集,包含训练集图片和标签、测试集图片和标签。
- 数据预处理:从训练集和测试集中筛选出标签为 0 和 1 的图片。
- 逻辑回归的实现:logits 定义逻辑回归的计算。loss_tensor 定义了损失的计算。
- 开启会话后,在每次迭代中,sess.run() 函数的输入是计算图和训练数据,输出误差值。
- 模型评估,计算准确率。
-
多层感知机
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 TensorFlow 低阶 API,利用多层感知机对 MNIST 手写数字图片进行分类。由于训练集规模较大,为了加快模型训练的速度,每次使用一个 batch 的进行训练。
解决用户的问题:利用计算机代替人类做手写数字识别的重复性劳动。
算法流程:
-
在 necessary flags, learning rate flags, status flags 中定义一些常量。其中 initial_learning_rate 表示初始的学习率,learning_rate_decay_factor 表示梯度下降的衰减率,num_epochs_per_decay 表示几次迭代衰减一次,fine_tuning 表示在大数据集上预训练来获得更好的效果,allow_ssoft_placement 表示如果制定的设备不存在,允许自动分配设备,log_devece_placement 表示是否打印设备分配日志。
-
在 load and organize data 中,input_data.read_data_sets(“MNIST_data/”, reshape=True, one_hot=True) 函数下载了 MNIST 数据集。第一个参数表示要获取的数据集。reshape 参数默认为 True 表示提取特征向量,训练数据的大小为 (55000, 784),为 False 表示获取原始图片,训练数据的大小为 (55000, 28, 28, 1)。one_hot 为 True 表示用非 0 即 1 的数组表示标签,训练标签的大小为 (55000, 10), 为 False 训练标签的大小为 (55000, )。划分训练集和测试集,训练数据大小为 (55000, 784),训练数据标签为 (55000, 10),测试数据大小为 (10000, 784),测试标签大小为 (10000, 10)。
-
在 defining graph 中,首先定义了一个默认的计算图。
-
在 parameters 中,tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase=False, name=None) 函数用来计算指数衰减的学习率,计算公式是$decayed_learning_rate=learning_rate*decay_rate^{(global_step / decay_steps)}$。
其中,learning_rate 表示初始的学习率,global_step 表示全局步数,传入一个初始值为 0 的张量,decay_steps 赋值为训练集样本数/批大小*每次衰减的迭代次数,decay_rate 表示衰减率,staircase 为 True 时,global_step / decay_steps 只计算整数部分。
-
在 defining place holders 中,定义了占位符。
tf.Variable 和 tf.placeholder 的区别:tf.Variable 是可训练变量,如权重 weights 或者偏置值 bias,声明时必须提供初始值。tf.placeholder 不必指定初始值,可在运行时,通过 Session.run 函数的 feed_dict 参数指定,仅仅作为一种占位符。
tf.one_hot 函数用于将张量转化为 one_hot 形式。其中,第一个参数是张量,depth 参数是 one_hot 的维度,axis 参数默认是 -1,表示在新的维度上建立 one_hot。
-
在 model + loss + accuracy 中,利用 tf.contrib.layers.fully_connected 函数定义了带有两个隐藏层的多层感知机。其中,参数 inputs 为输入的一个张量,参数 num_outputs 为输出的维度。tf.reduce_mean 函数用于计算张量 tensor 沿着指定的数轴(tensor 的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。tf.nn.softmax_cross_entropy_with_logits 函数用于计算 logits 和 labels 之间的交叉熵。tf.argmax(vector, 1):返回的是vector中的最大值的索引号。
-
在 training operation 中,optimizer.apply_gradients 函数的第一个参数是梯度张量,global_step 参数在每次 train_op 执行的时候自动加一。
-
在 define summaries 中,利用 tf.summary.scalar 和 tf.summary.merge_all 定义 summary。
-
在 run session 中,设置如果指定的设备不存在,允许自动分配设备,以及不打印设备分配日志。在每一个 epoch 中,在每一个 batch 中,找出这个 batch 对应的训练数据和标签。sess.run 函数第一个参数是张量的列表,feed_dict 参数提供占位符的值,依次返回张量列表中张量的值。在每一个 epoch 中,在训练集和测试集上分别计算损失和准确率。
-
-
RNN
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 TensorFlow 低阶 API,利用 RNN 对 MNIST 手写数字图片进行分类。由于训练集规模较大,为了加快模型训练的速度,每次使用一个 batch 的进行训练。
解决用户的问题:利用计算机代替人类做手写数字识别的重复性劳动。
算法流程:
- 定义常量。其中 hidden_size 是 RNN 隐藏层的神经元数。
- 将计算图重置为默认的计算图,利用 seed 设置随机数种子。
- 利用 tf.placeholder 函数定义 X 和 y 的占位符,其中第一个参数是数据类型,shape 参数是张量的大小,某一维度为 None 表示可以是任何大小。
- 定义模型。tf.nn.rnn_cell.BasicRNNCell 函数定义一个基本的 RNN 细胞,第一个参数是隐藏层的细胞数。tf.nn.dynamic_rnn 函数创建一个 RNN 神经网络,第一个参数是基本的 RNN 细胞。返回 outputs 是创建的 RNN 神经网络,state 是最终状态。tf.layers.dense 函数产生一个稠密连接的网络,第一个参数是 state,即 RNN 神经网络的输出大小,第二个参数是 output_size.
- 定义评估指标。tf.nn.in_top_k组要是用于计算预测的结果和实际结果的是否相等,返回一个bool类型的张量,tf.nn.in_top_k(prediction, target, K):prediction就是表示你预测的结果,大小就是预测样本的数量乘以输出的维度,类型是tf.float32等。target就是实际样本类别的标签,大小就是样本数量的个数。K表示每个样本的预测结果的前K个最大的数里面是否含有target中的值,一般都是取1。
- 下载数据集,处理数据集。X.reshape 函数用来改变 X 的规模。
- 打开会话,训练模型、评估评价指标。mnist.train.next_batch 函数用来得到下一个 batch 的训练数据,参数是每一个 batch 的训练数据大小。
-
Softmax 回归
http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 TensorFlow 低阶 API,利用 Softmax 回归模型对 MNIST 手写数字图片进行分类。
解决用户的问题:利用计算机代替人类做手写数字识别的重复性劳动。
算法流程:
-
创建占位符,tf.placeholder 函数不需要初始化变量,第一个参数是数据类型,第二个参数是张量大小,None 表示任意值
x = tf.placeholder(“float”, [None, 784])
-
创建需要训练的变量,tf.Variable 函数用于创建变量,第一个参数是初始值。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
-
定义模型,tf.matmul 函数表示张量的点乘运算,tf.nn.softmax 是 softmax 函数。
y = tf.nn.softmax(tf.matmul(x,W) + b)
Softmax 回归原理:
$y = softmax(Wx + b)$
$softmax(x) = normalize(exp(x))$
-
定义模型
定义占位符 y_ = tf.placeholder(“float”, [None,10])
计算交叉熵 cross_entropy = -tf.reduce_sum(y_*tf.log(y))
交叉熵损失函数:$H_{y’}y = -\sum_{i}y’{i}log(y’{i})$。其中,y 是我们预测的概率分布, y’ 是实际的分布。
要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
添加一个操作来初始化我们创建的变量,tf.initialize_all_variables 用来定义初始化所有变量的操作
init = tf.initialize_all_variables()
-
训练模型
启动模型,初始化变量。
sess = tf.Session()
sess.run(init)
让模型循环训练1000次。使用一小部分的随机数据来进行训练被称为随机训练(stochastic training),在这里更确切的说是随机梯度下降训练。
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
-
评估模型,tf.argmax(vector, 1):返回的是vector中的最大值的索引号。Sessopn.run 函数用来运行计算图,第一个参数是将要返回值的张量,feed_dict 参数是占位符的初始值。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, “float”))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
-
-
多层卷积网络
http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 TensorFlow 低阶 API,利用卷积神经网络对 MNIST 手写数字图片进行分类。
解决用户的问题:利用计算机代替人类做手写数字识别的重复性劳动。
算法流程:
-
权重初始化
模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。以下两个函数分别初始化权重和偏置,参数为张量的大小。tf.truncated_normal 函数用于产生随机数张量,第一个参数表示张量的形状,stddev参数表示标准差。 tf.constant 函数用于产生常量的张量,shape 表示张量的形状。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
-
卷积和池化
卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。
https://zhuanlan.zhihu.com/p/26139876
tf.nn.conv2d 是实现卷积计算的核心步骤函数。卷积的意思就是从图像的像素点上抽象出特征,然而这个特征抽取的过程并不是传统意义上的人工的抽取,而是通过卷积核进行自动抽取,当然这种抽取的结果对于人类来说也很难讲有什么能够解释的意义。卷积核像一小块方形的抹布,在图片上由上到下从左到右均匀抹过,并不时的停下来,当抹布停下来的时候,抹布上的点就会和其覆盖的点进行计算,得到一个值,这个值就将成为卷积计算输出矩阵的对应点的值。
input:输入图片,格式为[batch,长,宽,通道数],长和宽比较好理解,batch就是一批训练数据有多少张照片,通道数实际上是输入图片的三维矩阵的深度,如果是普通灰度照片,通道数就是1,如果是RGB彩色照片,通道数就是3,当然这个通道数完全可以自己设计。
filter:就是卷积核,其格式为[长,宽,输入通道数,输出通道数],其中长和宽指的是本次卷积计算的“抹布”的规格,输入通道数应当和input的通道数一致,输出通道数可以随意指定。
strides:是步长,一般情况下的格式为[1,长上步长,宽上步长,1],所谓步长就是指抹布(卷积核)每次在长和宽上滑动多少会停下来计算一次卷积。这个步长不一定要能够被输入图片的长和宽整除。
padding:是卷积核(抹布)在边缘处的处理方法。valid模式在边缘采取的是“不及”的方法,而same则是“过”的策略,两者效果孰优孰略取决于你的数据在边缘有没有什么重要信息。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=’SAME’)
池化用简单传统的2x2大小的模板做max pooling。
tf.nn.max_pool 是CNN当中的最大值池化操作,其实用法和卷积很类似。第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape。
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1。
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]。
第四个参数padding:和卷积类似,可以取’VALID’ 或者’SAME’。
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding=’SAME’)
-
第一层卷积
它由一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)。
x_image = tf.reshape(x, [-1,28,28,1])
把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
-
第二层卷积
把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
-
密集连接层
图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7764])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
-
Dropout
为了减少过拟合,在输出层之前加入dropout。用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。
keep_prob = tf.placeholder(“float”)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
-
输出层
最后,添加一个softmax层,就像前面的单层softmax regression一样。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
-
训练和评估模型
用更加复杂的ADAM优化器来做梯度最速下降,在feed_dict中加入额外的参数keep_prob来控制dropout比例。然后每100次迭代输出一次日志。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, “float”))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print “step %d, training accuracy %g”%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print “test accuracy %g”%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
-
-
使用 Estimator 构建卷积神经网络
https://www.tensorflow.org/tutorials/estimators/cnn
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:使用 Estimator,利用卷积神经网络对 MNIST 手写数字图片进行分类。
解决用户的问题:利用计算机代替人类做手写数字识别的重复性劳动。
运行代码遇到的问题:https://github.com/tensorflow/tensorflow/issues/24524
算法流程:
-
输入层
输入张量的形状应该为 [batch_size, image_height, image_width, channels]
tf.reshape 函数用来改变张量形状,批次大小为 -1,表示动态计算此维度。
input_layer = tf.reshape(features[“x”], [-1, 28, 28, 1])
-
卷积层1
在我们的第一个卷积层中,我们需要将 32 个 5x5 过滤器应用到输入层,并应用 ReLU 激活函数。
tf.layers.conv2d 函数用于创建卷积层。
inputs 参数指定输入张量,该张量的形状必须为 [batch_size, image_height, image_width, channels]。
filters 参数指定要应用的过滤器数量(在此教程中为 32)。
kernel_size 将过滤器的维度指定为 [height, width]。
padding 参数指定以下两个枚举值之一(不区分大小写):valid(默认值)或 same。要指定输出张量与输入张量具有相同的高度和宽度值,我们在此教程中设置 padding=same,它指示 TensorFlow 向输入张量的边缘添加 0 值,使高度和宽度均保持为 28。
activation 参数指定要应用于卷积输出的激活函数。我们使用 tf.nn.relu 指定 ReLU 激活函数。
conv2d() 生成的输出张量的形状为 [batch_size, 28, 28, 32]:高度和宽度维度与输入相同,但现在有 32 个通道,用于保存每个过滤器的输出。
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding=”same”,
activation=tf.nn.relu)
-
池化层 1
该层使用 2x2 过滤器和步长 2 执行最大池化运算。
tf.layers.max_pooling2d 函数用于创建池化层。
inputs 指定输入张量,形状为 [batch_size, image_height, image_width, channels]。在此教程中,输入张量是 conv1,即第一个卷积层的输出,形状为 [batch_size, 28, 28, 32]。
pool_size 参数将最大池化过滤器的大小指定为 [height, width](在此教程中为 [2, 2])。如果两个维度的值相同,则可以改为指定单个整数(例如 pool_size=2)。
strides 参数指定步长的大小。在此教程中,我们将步长设置为 2,表示过滤器提取的子区域在高度和宽度维度方面均应以 2 个像素分隔(对于一个 2x2 过滤器而言,这意味着提取的任何区域都不会重叠)。如果您要为高度和宽度设置不同的步长值,则可以改为指定元组或列表(例如 stride=[3, 6])。
max_pooling2d() (pool1) 生成的输出张量的形状为 [batch_size, 14, 14, 32]:2x2 过滤器将高度和宽度各减少 50%。
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
-
卷积层 2 和池化层 2
对于卷积层 2,我们配置 64 个 5x5 过滤器,并应用 ReLU 激活函数;对于池化层 2,我们使用与池化层 1 相同的规格(一个 2x2 最大池化过滤器,步长为 2)。
conv2 的形状为 [batch_size, 14, 14, 64]。
pool2 的形状为 [batch_size, 7, 7, 64]。
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding=”same”,
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
-
密集层
向 CNN 添加密集层(具有 1024 个神经元和 ReLU 激活函数),以对卷积/池化层提取的特征执行分类。
会先扁平化特征图 (pool2),以将其变形为 [batch_size, features],使张量只有两个维度。
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
tf.layers.dense 方法用于连接密集层。
inputs 参数指定输入张量:扁平化后的特征图 pool2_flat。
units 参数指定密集层中的神经元数量 (1024)。activation 参数会接受激活函数;同样,我们会使用 tf.nn.relu 添加 ReLU 激活函数。
为了改善模型的结果,使用 layers 中的 dropout 方法,向密集层应用丢弃正则化。
dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)
inputs 指定输入张量,即密集层 (dense) 的输出张量。
rate 参数指定丢弃率;在此教程中,我们使用 0.4,该值表示 40% 的元素会在训练期间被随机丢弃。
training 参数采用布尔值,表示模型目前是否在训练模式下运行;只有在 training 为 True 的情况下才会执行丢弃操作。在此教程中,我们检查传递到模型函数 cnn_model_fn 的 mode 是否为 TRAIN 模式。
输出张量 dropout 的形状为 [batch_size, 1024]。
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)
-
对数层
我们的神经网络中的最后一层是对数层,该层返回预测的原始值。我们创建一个具有 10 个神经元(介于 0 到 9 之间的每个目标类别对应一个神经元)的密集层,并应用线性激活函数(默认函数)。CNN 的最终输出张量 logits 的形状为 [batch_size, 10]。
logits = tf.layers.dense(inputs=dropout, units=10)
-
生成预测
predictions = {
“classes”: tf.argmax(input=logits, axis=1),
“probabilities”: tf.nn.softmax(logits, name=”softmax_tensor”)
}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
-
计算损失
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
-
配置训练操作
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(
loss=loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)
-
添加评估指标
eval_metric_ops = {
“accuracy”: tf.metrics.accuracy(
labels=labels, predictions=predictions[“classes”])}
return tf.estimator.EstimatorSpec(
mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)
-
加载训练和测试数据
# Load training and eval data
mnist = tf.contrib.learn.datasets.load_dataset(“mnist”)
train_data = mnist.train.images # Returns np.array
train_labels = np.asarray(mnist.train.labels, dtype=np.int32)
eval_data = mnist.test.images # Returns np.array
eval_labels = np.asarray(mnist.test.labels, dtype=np.int32)
-
创建 Estimator
model_fn 参数指定用于训练、评估和预测的模型函数。
model_dir 参数指定要用于保存模型数据(检查点)的目录。
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn, model_dir=”/tmp/mnist_convnet_model”)
-
设置日志记录的钩子
由于 CNN 可能需要一段时间才能完成训练,因此我们设置一些日志记录,以在训练期间跟踪进度。tf.train.LoggingTensorHook,它将记录 CNN 的 softmax 层的概率值。
我们将要记录的张量字典存储到 tensors_to_log 中。每个键都是我们选择的将会显示在日志输出中的标签,而相应标签是 TensorFlow 图中 Tensor 的名称。在此教程中,我们可以在 softmax_tensor(我们之前在 cnn_model_fn 中生成概率时为 softmax 操作指定的名称)中找到 probabilities。
接下来,我们创建 LoggingTensorHook,将 tensors_to_log 传递到 tensors 参数。我们设置 every_n_iter=50,指定每完成 50 个训练步之后应记录概率。
# Set up logging for predictions
tensors_to_log = {“probabilities”: “softmax_tensor”}
logging_hook = tf.train.LoggingTensorHook(
tensors=tensors_to_log, every_n_iter=50)
-
训练模型
在 numpy_input_fn 调用中,我们将训练特征数据和标签分别传递到 x(作为字典)和 y。我们将 batch_size 设置为 100(这意味着模型会在每一步训练 100 个小批次样本)。 num_epochs=None 表示模型会一直训练,直到达到指定的训练步数。我们还设置 shuffle=True,以随机化处理训练数据。在 train 调用中,我们设置 steps=20000(这意味着模型总共要训练 20000 步)。为了在训练期间触发 logging_hook,我们将其传递到 hooks 参数
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={“x”: train_data},
y=train_labels,
batch_size=100,
num_epochs=None,
shuffle=True)
mnist_classifier.train(
input_fn=train_input_fn,
steps=20000,
hooks=[logging_hook])
-
评估模型
要创建 eval_input_fn,我们设置 num_epochs=1,以便模型评估一个数据周期的指标,并返回结果。我们还设置 shuffle=False 以按顺序遍历数据。
# Evaluate the model and print results
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={“x”: eval_data},
y=eval_labels,
num_epochs=1,
shuffle=False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
print(eval_results)
-
-
使用 Keras 训练首个神经网络:基本分类
https://www.tensorflow.org/tutorials/keras/basic_classification
输入数据:Fashion MNIST 数据集。

输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 tf.keras 编写神经网络模型对 Fashon MNIST 图片进行分类。
解决用户的问题:利用计算机代替人类做识别图像的重复性工作。
算法流程:
- 导入 Fashion MNIST 数据集。keras.datasets.fashion_mnist.load_data 函数用于导入这个数据集。
- 预处理数据。将介于 0 到 255 的像素值缩小到 0 到 1 之间。
- 设置模型的层。 tf.keras.Sequential 函数用于连接不同的层,参数是一个不同层组成的列表。tf.keras.layers.Flatten 函数用于建立一位数组的层,参数是输入形状。tf.keras.layers.Dense 函数用于建立密集连接或全连接神经层,参数是神经元和激活函数。
- 编译模型。调用 model.compile 函数指定模型的损失函数、优化器、指标。
- 训练模型。调用 model.fit 函数训练模型,传入训练数据、训练标签、迭代次数。
- 评估准确率。调用 model.evaluate 函数测试模型,传入训练数据、训练标签。
- 做出预测。调用 model.predict 函数对测试集做出预测,传入测试数据,返回每个测试集在每个类上模型计算出的概率。
-
使用 Keras 进行影评文本分类
https://www.tensorflow.org/tutorials/keras/basic_text_classification
输入数据:IMDB 影评数据集,包含 50000 条影评文本。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 tf.keras 编写神经网络模型对 IMDB 影评数据集进行分类。
解决用户的问题:利用计算机代替人类做识别图像的重复性工作。
算法流程:
-
下载 IMDB 数据集。imdb.load_data 函数用于导入这个数据集。
-
将整数转为回字词。下载下来的数据已经将文本转换成数字,可以利用 imdb.get_word_index 函数得到每个单词的索引。
-
准备数据。由于每段影评长度不一样,而深度学习必须将影评转换成张量才可以馈送到神经网络中。利用 pad_sequences 函数将每个样本长度标准化,输入参数为训练数据,value 参数为用来补齐的值,padding为 ‘pre’ 或 ‘post’ ,在序列的前端补齐还是在后端补齐,maxlen为所有序列的最大长度。
-
构建模型。利用 keras.Sequential 函数链接不同的神经网络层。
第一层是 Embedding 层。该层会在整数编码的词汇表中查找每个字词-索引的嵌入向量。模型在接受训练时会学习这些向量。这些向量会向输出数组添加一个维度。生成的维度为:(batch, sequence, embedding)。
接下来,一个 GlobalAveragePooling1D 层通过对序列维度求平均值,针对每个样本返回一个长度固定的输出向量。这样,模型便能够以尽可能简单的方式处理各种长度的输入。
该长度固定的输出向量会传入一个全连接 (Dense) 层(包含 16 个隐藏单元)。
最后一层与单个输出节点密集连接。应用 sigmoid 激活函数后,结果是介于 0 到 1 之间的浮点值,表示概率或置信水平。
-
损失函数和优化器。调用 model.compile 函数指定模型的损失函数、优化器、指标。
-
创建验证集。从原始训练数据中分离出 10000 个样本,创建一个验证集。
-
训练模型。调用 model.fit 函数训练模型,在训练期间,监控模型在验证集的 10000 个样本上的损失和准确率。model.fit 函数的参数为训练集数据、训练集标签、迭代数、小批次的大小、验证集,verbose为日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录。
-
评估模型。调用 model.evaluate 函数测试模型,传入训练数据、训练标签。
-
创建准确率和损失随时间变化的图。history.history 得到训练集和验证集上的准确率、损失的变化。
-
-
保存和恢复模型
https://www.tensorflow.org/tutorials/keras/save_and_restore_models
输入数据:MNIST 手写数字数据集。
输出数据:每一次迭代的损失和准确率,迭代完成后的准确率。
总体功能:利用 tf.keras 将模型进度在训练期间和之后保存。
解决用户的问题:可以从上次暂停的地方继续训练模型,避免训练时间过长。此外,可以保存意味着可以分享模型,而他人可以对工作成果进行再创作。
算法流程:
-
获取示例数据集。tf.keras.datasets.mnist.load_data 函数获取 MNIST 数据集。
-
定义模型。tf.keras.Sequential 函数用于连接不同的层,参数是一个不同层组成的列表。tf.keras.layers.Dense 函数用于建立密集连接或全连接神经层,参数是神经元和激活函数。tf.keras.Dropout 函数指定丢弃层,传入输入的丢弃率。调用 model.compile 函数指定模型的损失函数、优化器、指标。调用 model.summary() 打印模型的概要。
-
在训练期间保存检查点
调用 tf.keras.callbacks.ModelCheckpoint 函数建立检查点回调,传入检查点路径参数,period 参数用于指定隔多少个周期保存一次,verbose 参数为日志显示,save_weights_only 参数为是否只保存权重。
训练模型,并将 ModelCheckpoint 回调传递给该模型。
调用 model.load_weights(checkpoint_path) 加载权重。
-
手动保存权重
model.save_weights(checkpoint_path) 函数用于保存权重。
model.load_weights(checkpoint_path) 函数用于加载权重。
-
保存整个模型
model.save(‘my_model.h5’) 函数用于保存模型。
new_model = keras.models.load_model(‘my_model.h5’) 函数用于加载模型。
-
-
探索过拟合和欠拟合
https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
输入数据:IMDB 影评数据集。
输出数据:在基准模型、小模型、大模型上的训练损失和验证损失。
总体功能:利用 tf.keras 编写探索模型的过拟合和欠拟合。
解决用户的问题:模拟过拟合和欠拟合的情形,以便采取相应的策略。
算法流程:
-
下载 IMDB 数据集
multi_hot_sequences 函数对句子进行多热编码。输入句子列表和维度,返回句子数*维度的矩阵。
-
演示过拟合
使用
Dense层创建一个简单的基准模型(每层 16 个神经元),然后创建更小(每层 4 个神经元)和更大的版本(每层 512 个神经元),并比较这些版本。 -
创建一个更小的模型
-
创建一个更大的模型
-
绘制训练损失和验证损失图表
结论:较大的网络几乎仅仅 1 个周期之后便立即开始过拟合,并且之后严重得多。网络容量越大,便能够越快对训练数据进行建模(产生较低的训练损失),但越容易过拟合(导致训练损失与验证损失之间的差异很大)。
-
缓解过拟合的策略
-
添加权重正则化
要缓解过拟合,一种常见方法是限制网络的复杂性,具体方法是强制要求其权重仅采用较小的值,使权重值的分布更“规则”。这称为“权重正则化”,通过向网络的损失函数添加与权重较大相关的代价来实现。这个代价分为两种类型:
- L1 正则化,其中所添加的代价与权重系数的绝对值(即所谓的权重“L1 范数”)成正比。
- L2 正则化,其中所添加的代价与权重系数值的平方(即所谓的权重“L2 范数”)成正比。L2 正则化在神经网络领域也称为权重衰减。不要因为名称不同而感到困惑:从数学角度来讲,权重衰减与 L2 正则化完全相同。
在
tf.keras中,权重正则化的添加方法如下:将权重正则化项实例作为关键字参数传递给层。现在,我们来添加 L2 权重正则化。l2(0.001)表示层的权重矩阵中的每个系数都会将0.001 * weight_coefficient_value**2添加到网络的总损失中。请注意,由于此惩罚仅在训练时添加,此网络在训练时的损失将远高于测试时。 -
添加丢弃层
丢弃(应用于某个层)是指在训练期间随机“丢弃”(即设置为 0)该层的多个输出特征。假设某个指定的层通常会在训练期间针对给定的输入样本返回一个向量 [0.2, 0.5, 1.3, 0.8, 1.1];在应用丢弃后,此向量将随机分布几个 0 条目,例如 [0, 0.5, 1.3, 0, 1.1]。“丢弃率”指变为 0 的特征所占的比例,通常设置在 0.2 和 0.5 之间。在测试时,网络不会丢弃任何单元,而是将层的输出值按等同于丢弃率的比例进行缩减,以便平衡以下事实:测试时的活跃单元数大于训练时的活跃单元数。
在 tf.keras 中,您可以通过丢弃层将丢弃引入网络中,以便事先将其应用于层的输出。
-
获取更多训练数据
-
降低网络容量
-
-
-
在启用 Eager Execution 的情况下使用 RNN 生成文本
https://www.tensorflow.org/tutorials/sequences/text_generation
输入数据:Andrej Karpathy 在 The Unreasonable Effectiveness of Recurrent Neural Networks 一文中提供的莎士比亚作品数据集。
输出数据:自动生成的文本。
总体功能:在启用 Eager Execution 的情况基于字符使用 RNN 生成文本。
解决用户的问题:文本自动生成。
算法流程:
-
下载莎士比亚数据集
tf.keras.utils.get_file 函数用于下载数据集,参数为文件名和下载页面地址。
-
向量化文本
创建两个对照表:一个用于将字符映射到数字,另一个用于将数字映射到字符。
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
-
创建训练样本和目标
将文本划分为训练样本和训练目标。每个训练样本都包含从文本中选取的
seq_length个字符。相应的目标也包含相同长度的文本,但是将所选的字符序列向右顺移一个字符。例如,假设seq_length为 4,我们的文本为“Hello”,则可以将“Hell”创建为训练样本,将“ello”创建为目标。步骤为:
- 将文本拆分成文本块,每个块的长度为
seq_length+1个字符 - 利用此文本块创建输入文本和目标文本
- 将文本拆分成文本块,每个块的长度为
-
使用 tf.data 创建批次文本并重排这些批次
使用 tf.data 将文本分成块。但在将这些数据馈送到模型中之前,我们需要对数据进行重排,并将其打包成批。
-
实现模型
-
实例化模型、优化器和损失函数
使用采用默认参数的 Adam 优化器,并用 softmax 交叉熵作为损失函数。此损失函数很重要,因为我们要训练模型预测下一个字符,而字符数是一种离散数据(类似于分类问题)。
-
训练模型

在此示例中,我们使用采用 GradientTape 的自定义训练循环。要详细了解此方法,请参阅 Eager Execution 指南。
- 首先,用零和形状(批次大小,RNN 单元数)初始化模型的隐藏状态。为此,我们将调用在创建模型时定义的函数。
- 然后,逐批对数据集进行迭代,并计算与该输入关联的预测和隐藏状态。
- 在训练过程中,发生了许多有趣的现象:
- 模型获得隐藏状态(初始化为 0,我们称之为
H0)和第一批输入文本(我们称之为I0)。 - 然后,模型返回预测值
P1和H1。 - 对于下一批输入,模型收到
I1和H1。 - 现在,有趣的是我们将
H1随I1一起传递给模型,模型正是通过这种方式进行学习。从各个批次中学习到的上下文将包含到隐藏状态中。 - 重复上述操作,直到数据集中的数据全部用尽。然后开始一个新的周期,并重复此过程。
- 模型获得隐藏状态(初始化为 0,我们称之为
- 计算预测值后,使用上面定义的损失函数计算损失。然后,计算相对于模型变量的损失梯度。
- 最后,使用
apply_gradients函数在优化器的帮助下朝着训练的方向迈进一步。
-
使用训练的模型生成文本

使用代码块可生成文本:
- 首先选择一个起始字符串,初始化隐藏状态,并设置要生成的字符数。
- 使用起始字符串和隐藏状态获取预测值。
- 然后,使用多项分布计算预测字符的索引 - 将此预测字符用作模型的下一个输入。
- 模型返回的隐藏状态被馈送回模型中,使模型现在拥有更多上下文,而不是仅有一个单词。在模型预测下一个单词之后,经过修改的隐藏状态再次被馈送回模型中,模型从先前预测的单词获取更多上下文,从而通过这种方式进行学习。
-
-
Regression: predict fuel efficiency
https://www.tensorflow.org/tutorials/keras/basic_regression
输入数据:Auto MPG 数据集。
输出数据:汽车的燃油效率。
总体功能:预测 1970 年代后期和 1980 年代初期汽车的燃油效率。
解决用户的问题:解决回归问题,其目标是预测连续值的输出,例如价格或概率。与之相反的是分类问题。
算法流程:
- 获取数据
- 清洗数据
- 观察是否有未知值,将这些未知值所在的数据记录删去。
- 分割训练集、测试集
- 探索数据
- 观察训练集列的对的联合分布
- 从标签中分割为多个特征
- 将类型值转成 onehot
- 数据归一化
- 将每个值减去平均值,除以标准差
- 建立模型
- 模型为多层感知机,最后一层为一个神经元
- 使用 RMSprop 优化器
- 损失函数使用均方误差,指标使用均方误差和平均绝对误差
- 训练模型
- 做出预测
-
NeuMF
-
get_model 函数用于建立模型。
- 定义用户和物品的输入。
- 定义 MF 的用户、物品的嵌入层
- 定义 MLP 的用户、物品的嵌入层。
- MF 部分:将 MF 的用户、物品的嵌入层展平,然后做点积。
- MLP 部分:将 MLP 的用户、物品的嵌入层展平,然后拼接起来,再连接到几层全连接层,激活函数为 relu。
- 拼接 MF 和 MLP 部分。
- 最终预测层:一个神经元,激活函数为 sigmoid。
-
load_pretrain_model 用于加载预训练模型。
- 加载 MF 用户、物品的嵌入层的权重。
- 加载 MLP 用户、物品的嵌入层的权重。
- 加载 MLP 中间层的权重。
- 获取预测层的权重:加载 MF 和 MLP 的预测层的权重,计算预测层的权重。
-
get_train_instances 函数用于获得训练实例。
- 训练实例为训练集中的用户购买物品记录,以及随机采样的用户未购买物品的记录。
-
主函数
- topK 为给每个用户推荐的物品个数,影响 HR@K 和 NDCG@K 指标的具体值。
- 加载数据集,并计算训练集中的用户个数和物品个数。
- 建立模型代码中,模型的损失函数使用二元交叉熵。
- 训练模型,每次迭代中计算损失和指标。
-
评价指标
https://ask.hellobi.com/blog/wenwen/12289
在top-K推荐中,HR是一种常用的衡量召回率的指标,其计算公式如下:

分母是所有的测试集合,分子式每个用户top-K推荐列表中属于测试集合的个数的总和。举个简单的例子,三个用户在测试集中的商品个数分别是10,12,8,模型得到的top-10推荐列表中,分别有6个,5个,4个在测试集中,那么此时HR的值是 (6+5+4)/(10+12+8) = 0.5。
-